



Fifteen AI agents we see small teams ship and stick with in the first 90 days. Every one is in production at a ScubaDev client or in the Ideas library. Every one earns its retainer line item.
We grouped them: support agents that deflect ticket volume, ops and research agents that compress engineering time, and revenue and content agents that create new pipeline. Each comes with a stack opinion, a payback window, and the gotchas we have hit.
If you are picking two to ship first, jump to section five. The pair we recommend feeds the next three with data.
Below the surface
Fifteen production AI agents. Not fifteen demos. Not fifteen ideas on a slide. Fifteen patterns we have shipped, watched run, and replaced when the model layer shifted. They are grouped by where the load lives in a small team. Pick the two that touch your worst bottleneck and start there.



By the numbers
The fifteen agent map at a glance
-
Agents in this guide
15
Production patterns we ship and operate at ScubaDev clients.
-
Agents to ship first
2
The pair that compounds: in-app AI help plus inbox triage.
-
Time to first version
3 weeks
The fastest agents in this list reach a reviewed first version inside three weeks.
-
Month-one ROI
30 days
The window where the right agent should already pay back its build cost.






How to read this list
Each agent below carries the same three labels. Use them to spot the right next move for your team.
- 01
Effort
Weeks of engineering work for a typical small team. Momentum tier means 2 to 4 weeks. Deep end means 4 to 10 weeks. Anything beyond that and the agent should be split into two smaller wins.
- 02
Payback window
How fast the agent pays for itself in reduced headcount or faster revenue. Anything over six months we flag. Most agents on this list pay back inside thirty days, and the ones that do not have a structural reason.
- 03
Stack bias
Our opinion on what to build with. Most of these run on n8n plus an LLM API plus a small database. The exceptions are agents that need real-time voice, custom UI, or warehouse-scale data access.



03 / Common pattern
What they all have in common
Bounded data
Every agent on this list reads from a defined corpus, not the open web. Product docs, your past sent emails, your team calendar, your warehouse schema. Bounded data is what keeps token cost predictable and hallucinations rare.
Human in the loop
Every agent escalates. None of them auto-execute the high stakes call. Human judgment is the moat, the agent runs the routine ninety percent. The agents that try to remove the human entirely are the ones that ship and silently break.
Token discipline
Two stage classification. Cheap model for triage, capable model for the judgment call. Daily token cost alerts. Rollback path on prompt regressions. The agencies and teams that ship these patterns budget for tokens before they budget for features.

-
01 / In-app AI help that reads your docs
Users ask questions in the app. The AI answers from your actual product docs. Unanswered questions flow to support.
EffortMomentum, 2 to 3 weeksPaybackUnder 30 daysStackRetrieval over docs + LLM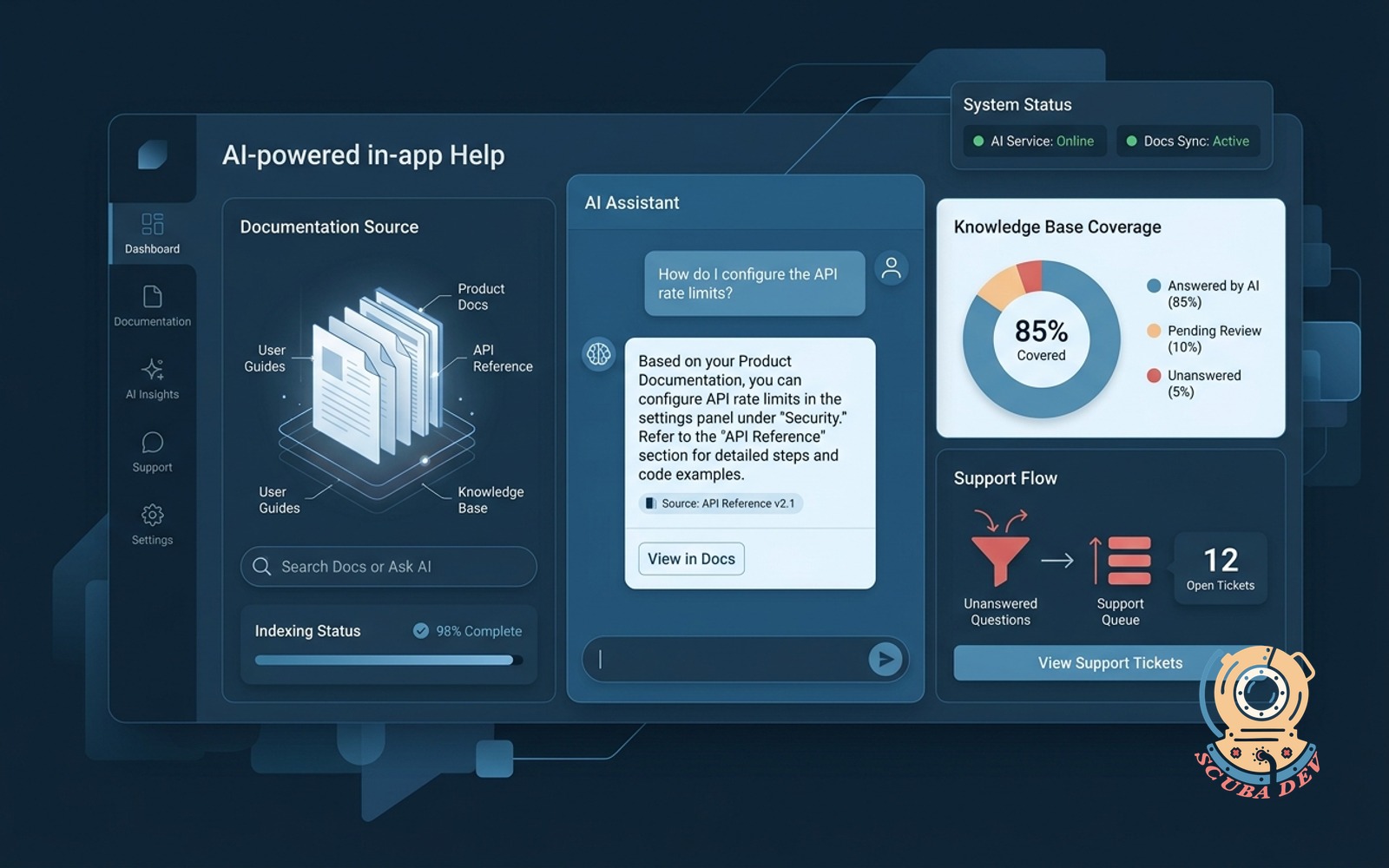
No new auth surface, bounded token budget, the docs already exist in a format the model can ingest, and the ROI shows up in support tickets the next week. For any SaaS with more than 100 users and real documentation, this is agent number one in any serious ai agent development program. We run this pattern on seven client accounts and the average support ticket reduction in the first 90 days is 40 to 60 percent.
Build notes. Use a retrieval augmented approach over your docs, not fine tuning. Cheap model for question classification, capable model for the answer. Log every unanswered question. That log is the fuel for agent number five below.
-
02 / Voice-first booking agent
Answers the phone, reads team calendars, books the right service with the right person, and sends a confirmation text.
EffortDepth, 4 to 6 weeksPayback30 to 60 daysStackRetell or Vapi + Twilio + Claude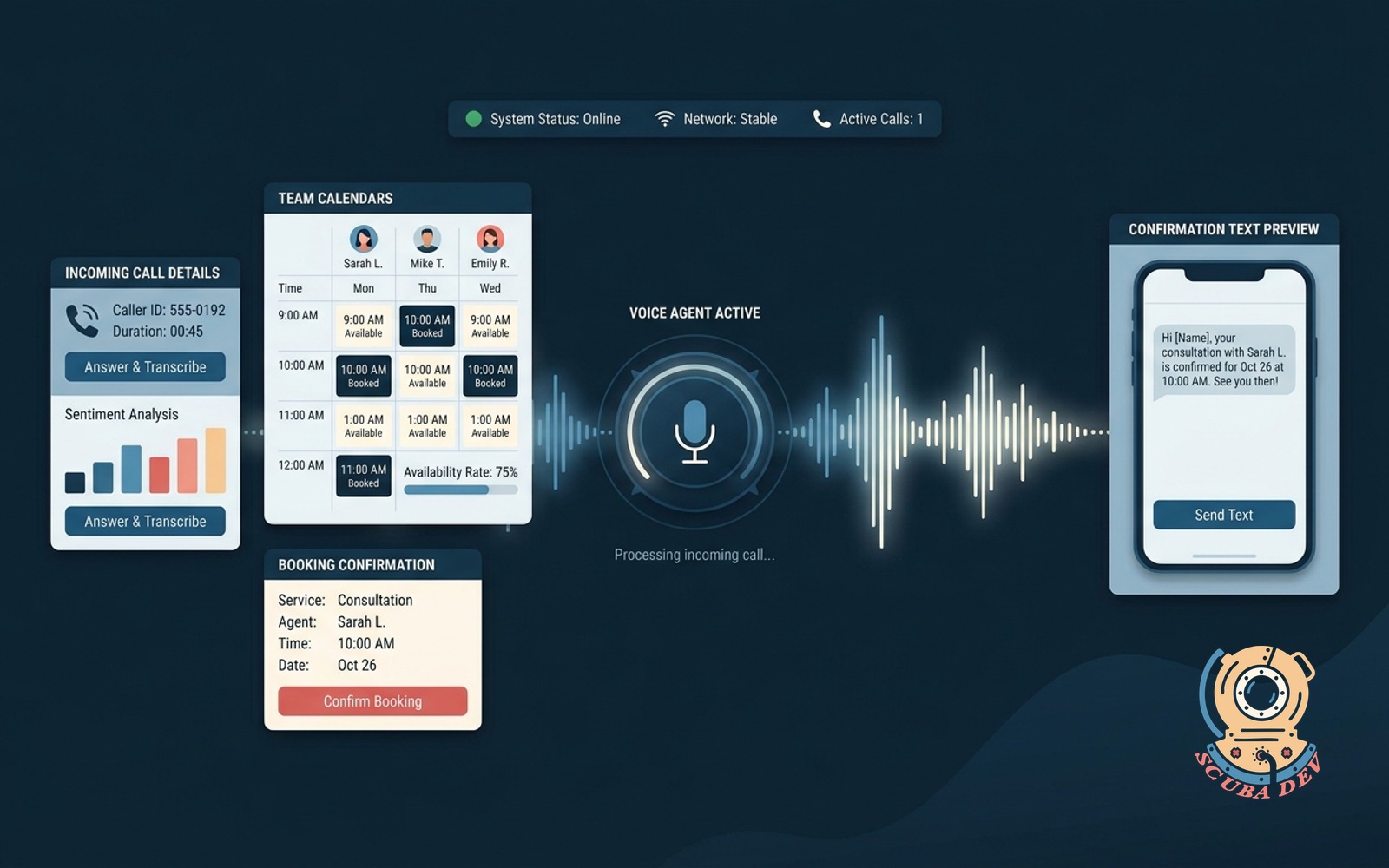
This is the Mermaid Phone pattern. The stack is Retell AI or Vapi for voice, Twilio for telephony, Claude for reasoning, and whatever calendar the client already uses. For any service business taking calls, salons, med spas, home service, small healthcare, this is the highest ROI agent in the list because it replaces a part time receptionist role.
Build notes. Latency is the make or break metric. Under 1.5 seconds between caller speech and agent response is where callers stop noticing the agent is AI. Budget engineering time for latency tuning, not feature breadth.
-
03 / Brand mention agent with sentiment
Watches the web and social for your brand. Summarizes daily, flags negative mentions for response.
EffortMomentum, 2 to 3 weeksPayback60 to 90 daysStackn8n + custom classifier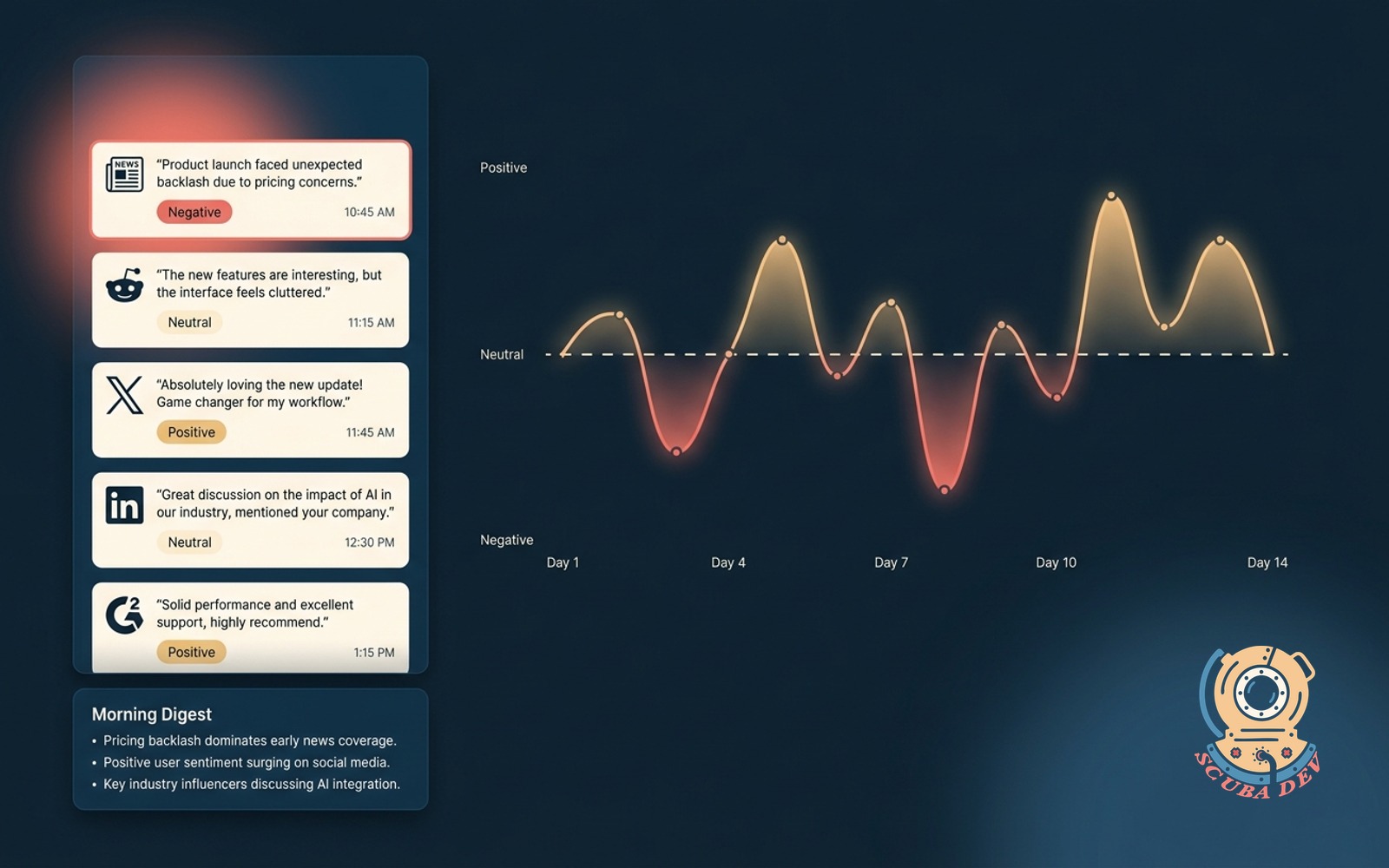
The trick is not the monitoring. The trick is the sentiment classifier that flags only what matters. Generic sentiment tools flag too many false positives. A brand specific classifier, trained on your past incidents, is the ROI.
Build notes. Start by labeling 100 past brand mentions as ignore, respond, or escalate. Use the labeled set as your classifier prompt. Log the classifier misses and relabel weekly for the first month.
-
04 / Inbox triage agent
Reads every new message, drafts the reply in your voice, files the rest, flags only what needs you.
EffortMomentum, 2 to 3 weeksPaybackUnder 30 daysStackTwo-stage LLM, no auto-send
This is the highest ROI agent for operators whose inbox is the bottleneck. Knowledge workers spend 28 percent of their week on email. A triage agent that deflects 40 percent of that with a good filing system buys back roughly a day a week per person.
Build notes. Voice capture is the hard part. Feed the agent 200 of your past sent emails as the style guide. Two stage classifier, cheap model for category, capable model for draft. Never auto send. Always human approval.
-
05 / Knowledge base gap analyzer
Clusters unanswered tickets into topics the knowledge base does not cover. Drafts the missing articles for approval.
EffortMomentum, 2 to 4 weeksPayback60 to 90 daysStackEmbedding clusters + LLM
This is the back half of agent 01. In-app AI help logs unanswered questions. This agent turns the log into articles. Together they compound: more articles, fewer unanswered questions, less support load, faster feedback loop.
Build notes. Run it weekly, not in real time. Cluster the unanswered question log by topic embedding. Output is a ranked list of missing articles. A human reviews, the agent drafts, a human publishes.
-
06 / Refund handling agent
Hears the request, checks policy, issues the refund or escalates, writes the note back to the customer.
EffortMomentum, 2 to 4 weeksPayback30 to 60 daysStackn8n + structured policy rules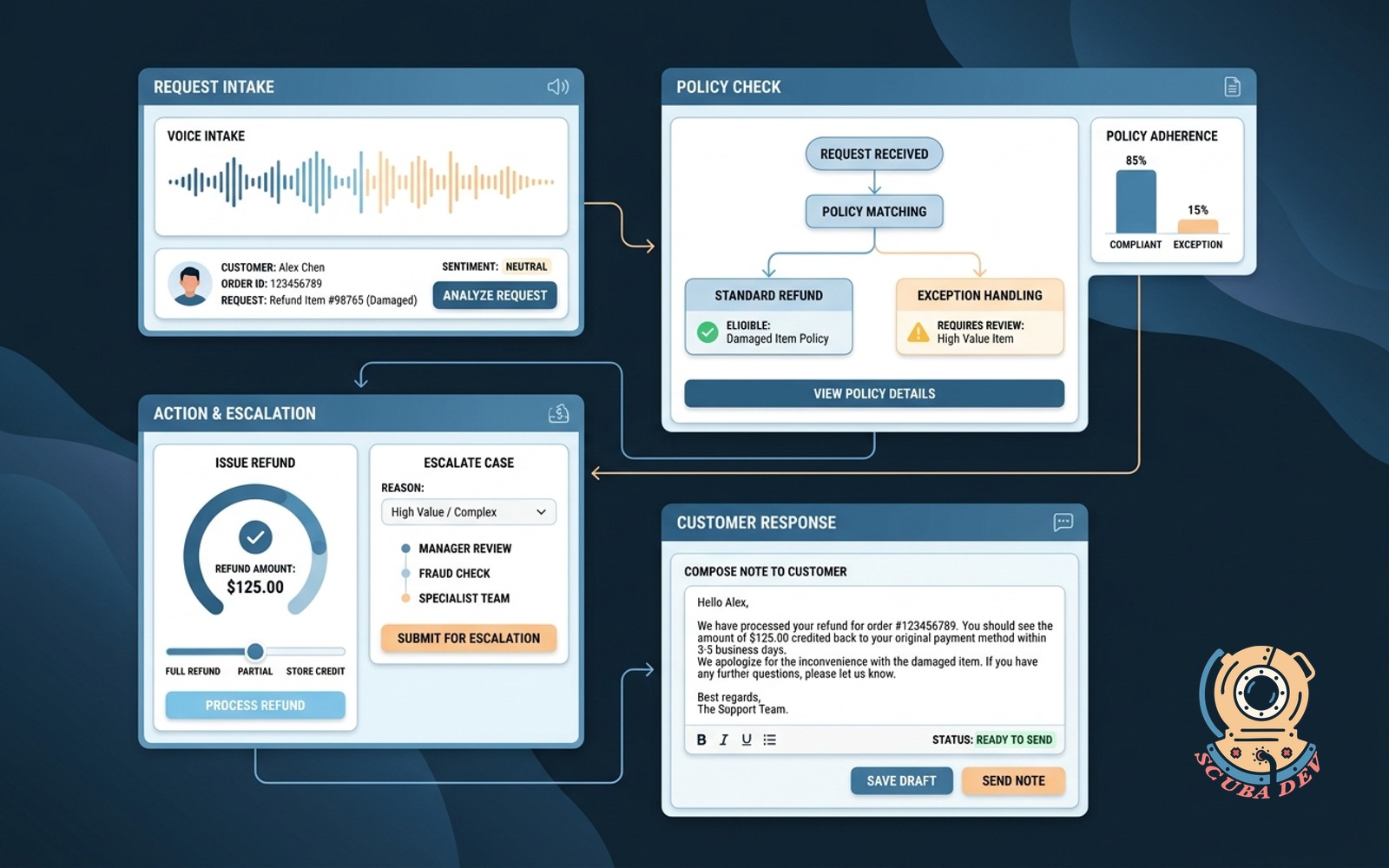
For ecommerce or subscription SaaS, refunds are the highest friction support interaction. Half of them are within policy and should be automatic. The other half require human judgment. The refund agent separates them.
Build notes. The policy has to be in structured form, not a PDF. Set the auto refund threshold conservatively at launch, expand as confidence grows. Log every decision with the exact rule it fired on.
-
07 / Post-purchase SMS concierge
After the order ships, the buyer can text questions about sizing, care, or returns. AI answers in brand voice and escalates real issues.
EffortMomentum, 2 to 4 weeksPayback30 to 60 daysStackTwilio SMS + Claude + Shopify
Ecommerce specific agent that pays back fast because it catches refund and return intent before it becomes a dispute. The stack is Twilio SMS plus Claude plus whatever order system the client runs.
Build notes. Opt in is legally required, TCPA in the US. Send the opt in inside the order confirmation email. Keep the agent scoped to post purchase questions only, not cross sell.

-
08 / Recruiter screening agent
Reads incoming applications, scores them against your hiring rubric, drafts the screening interview.
EffortDepth, 3 to 5 weeksPayback60 to 120 daysStackATS + Claude + rubric prompt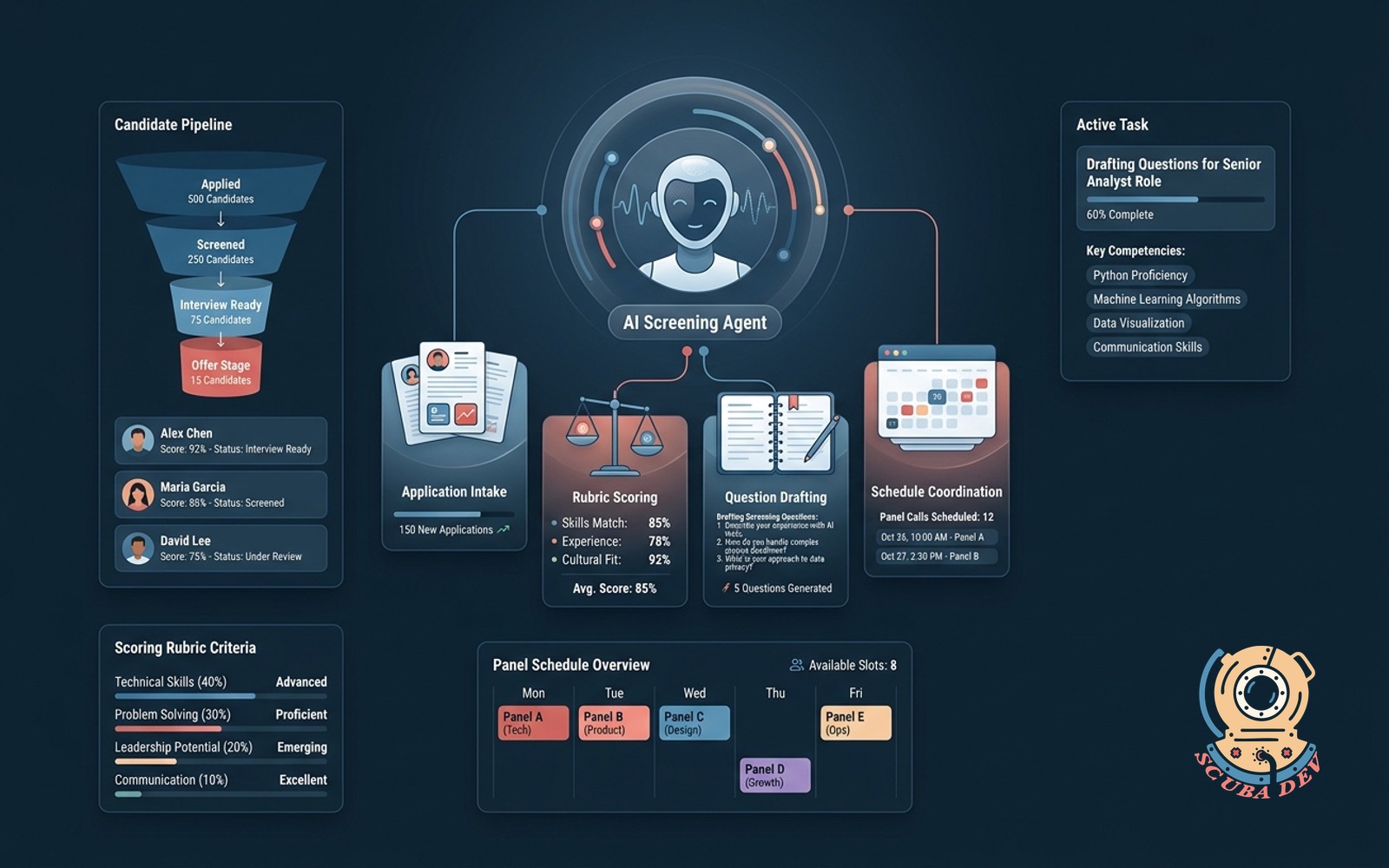
For any team hiring more than one role a quarter, the screening agent is hours of recruiter time per week. Not all of it. The judgment calls stay human. The first pass through 200 applications is the agent.
Build notes. The rubric must be explicit and rule based. Vague hiring criteria produce vague agent output. The first deployment usually exposes the fact that the rubric was never written down. That alone is worth the build.
-
09 / Candidate-screen scheduler agent
Coordinates interviewer calendars, candidate availability, room booking, reschedules, and reminders.
EffortMomentum, 2 to 3 weeksPayback60 to 120 daysStackCal.com or Calendly + LLM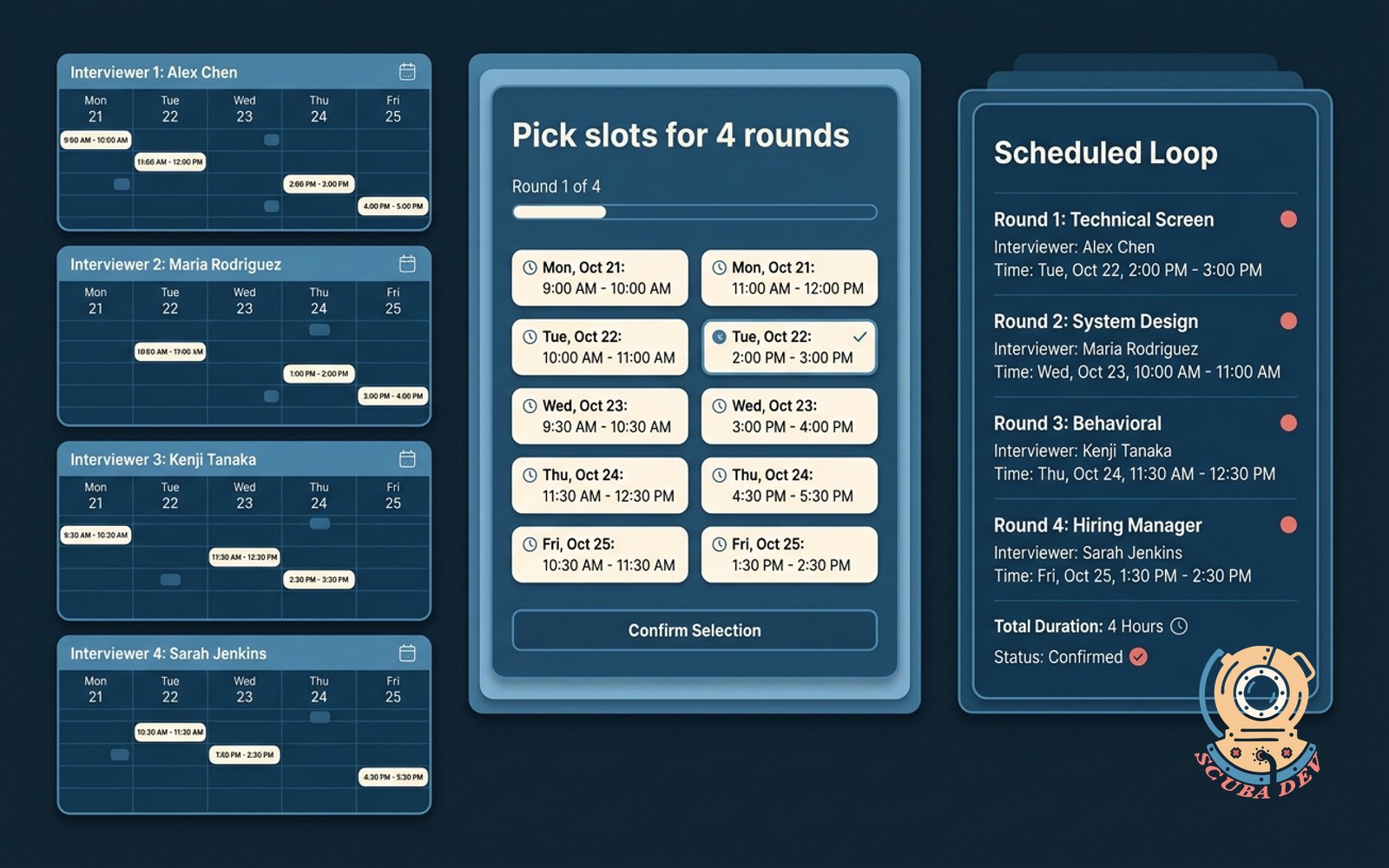
The scheduler is the small ops fix that prevents recruiter burnout. When interviewers cancel, the agent finds a backup, reschedules, and notifies everyone. When candidates ghost, it follows up. Without a recruiter touching it.
Build notes. Calendar integration is the long pole. Google Calendar plus Microsoft 365 covers 80 percent of cases. Build for both from day one or you are rewriting the agent at customer two.
-
10 / Research brief agent
Collects sources on a topic, synthesizes findings, exports a formatted brief to Notion or Drive.
EffortMomentum, 2 to 3 weeksPayback30 to 60 daysStackFirecrawl + Perplexity API
The research agent is the most under rated workflow on this list. Marketing teams use it for competitive briefs. Sales for account intel. Founders for market sizing. The output quality scales with how clearly the operator describes what they want.
Build notes. Tool use is mandatory. The agent needs web search, page fetch, and a structured output formatter. Anthropic's tool use plus Brave Search plus a Notion or Google Drive export integration is the cleanest stack.
-
11 / Error log triage agent
Watches the production error stream, scores severity, files the noise, escalates the real signal.
EffortMomentum, 2 to 3 weeksPayback60 to 120 daysStackn8n + Sentry or Datadog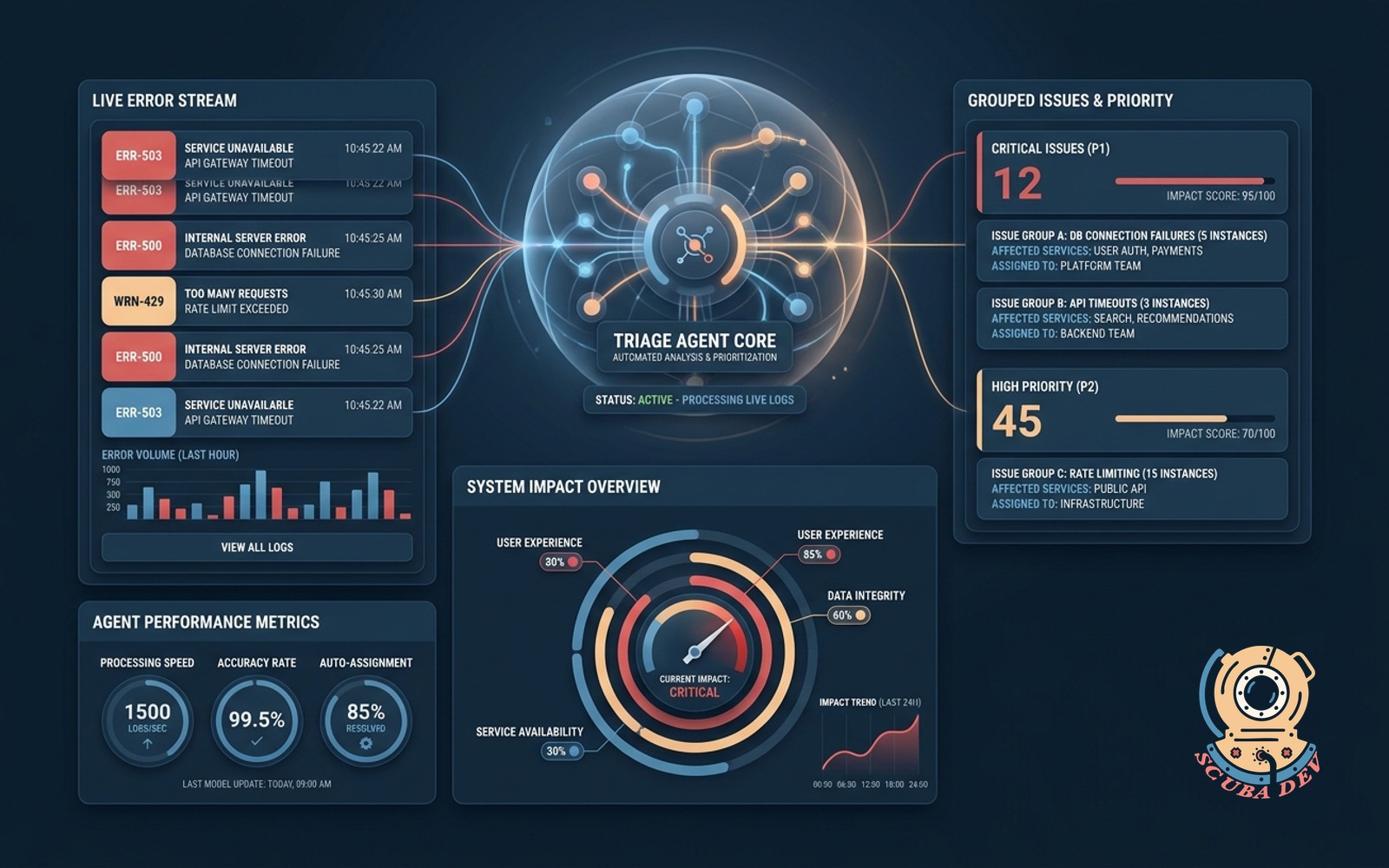
Every team running production has too many errors and not enough triage capacity. The triage agent turns a noisy Sentry feed into a prioritized inbox. Severity scoring against the system architecture is the value, not the alerting.
Build notes. Run on a five minute cron rather than real time. Cluster by stack trace fingerprint. Score against system criticality and user impact. Escalate only the top three each window.

-
12 / Conversational chatbot lead capture
Replaces the static contact form with a chat that qualifies on the first reply.
EffortMomentum, 1 to 2 weeksPaybackUnder 30 daysStackWidget + Claude + CRM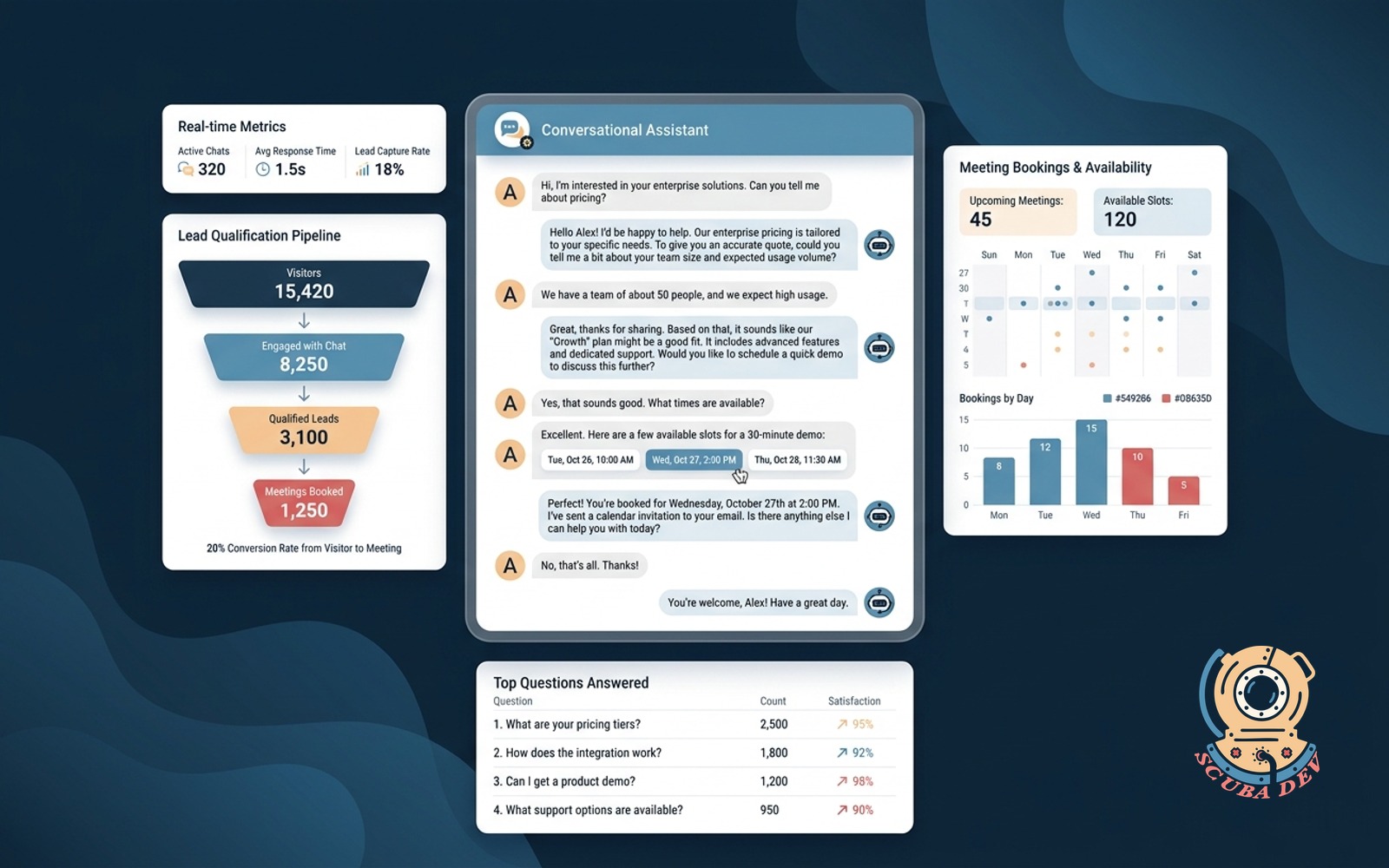
Static lead forms convert badly. Conversational capture asks the right next question based on what the visitor said, not a fixed list. Conversion rates lift 30 to 60 percent in the deployments we measure.
Build notes. The qualifier prompts must be tied to the actual sales playbook. Vague qualification produces vague leads. Train against your last 50 closed deals, not against a generic qualification framework.
-
13 / Brief to first draft writer agent
Takes a brief and your past writing samples, produces a first draft in your voice.
EffortMomentum, 2 to 4 weeksPayback30 to 60 daysStackLong-context LLM, no fine-tune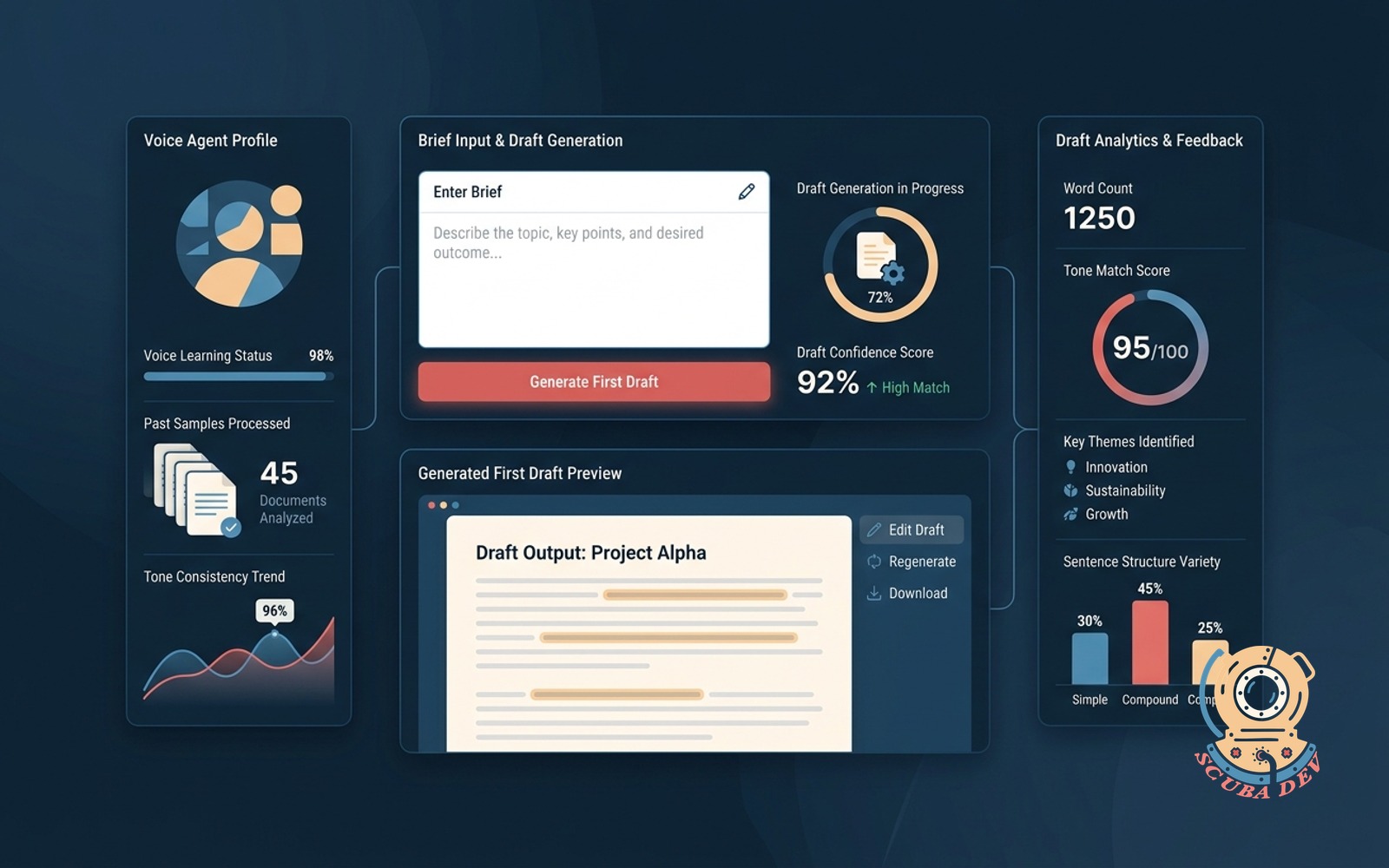
The writer agent is the highest visible ROI agent for marketing teams. Drafts that previously took two hours come out in fifteen minutes. The human edit pass is faster too because the structure is right from the start.
Build notes. Voice capture from past sent emails plus published content is the foundation. The draft is never the finished asset. Every draft routes to a human edit. Auto publishing is the failure mode.
-
14 / Sales battle card generator
Pulls competitor reviews, public pricing, and feature pages into a per-deal battle card.
EffortMomentum, 2 to 3 weeksPayback60 to 120 daysStackn8n + scrape + G2 ingest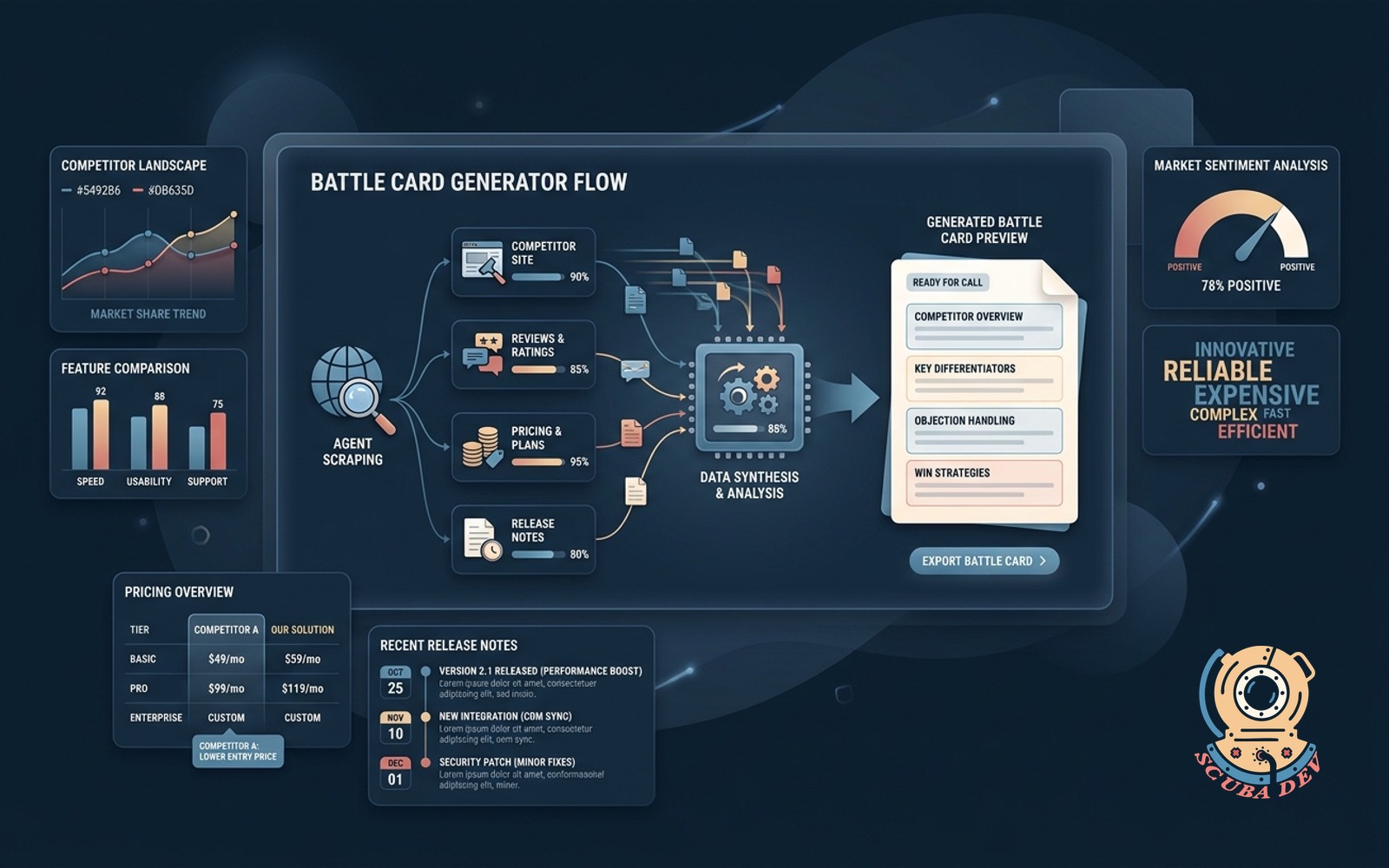
For B2B sales teams running competitive deals, the battle card agent is hours of research compressed into one document. Inputs: competitor name, deal context. Output: a structured battle card with weaknesses, common objections, and recommended counter narratives.
Build notes. Verifiable sources only. Every claim on the battle card cites a public source. Hallucinations on a battle card cost deals. Source verification is the moat.
-
15 / Ask your data conversational agent
Natural language questions about your warehouse data. The agent writes the SQL and returns the answer.
EffortDeep end, 4 to 10 weeksPayback120+ daysStackWarehouse SQL + LLM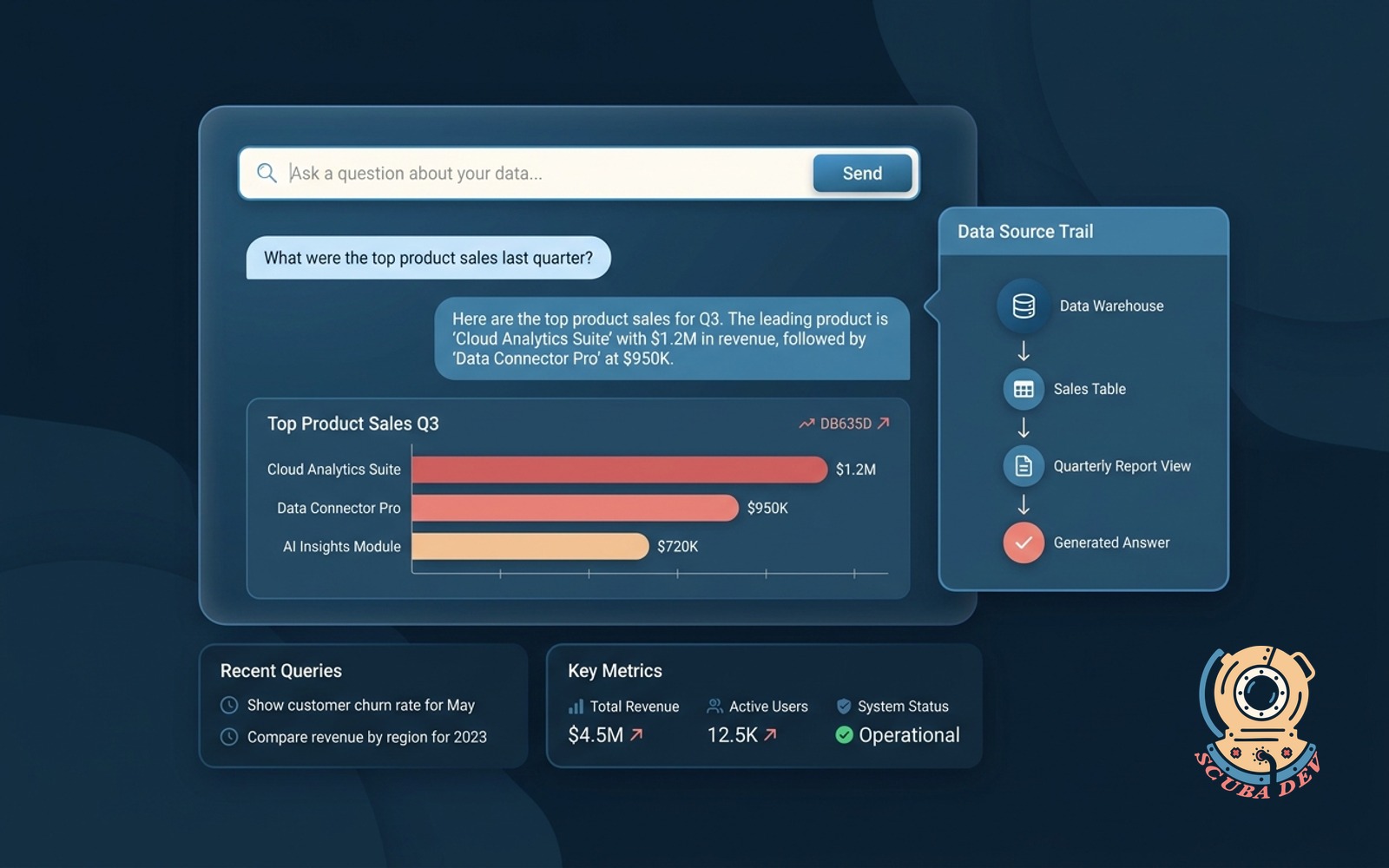
The data agent democratizes warehouse access. Operators ask questions like the analyst is on call. The agent writes parameterized SQL, runs it against a read replica, returns the result with the source query for verification.
Build notes. Schema documentation is the foundation. The agent is only as good as the table and column descriptions you feed it. Invest a week documenting the schema in plain English before building the agent or it will hallucinate joins.


Which two to ship first
If you have one quarter and one engineer, ship in-app AI help and inbox triage. Three reasons.
- 01
They address the two universal bottlenecks
Support load and communication load. Every company has both. Neither requires a data infrastructure investment. Both ship in under three weeks. Both show measurable ROI inside the first thirty days.
- 02
They compound
In-app AI help generates the unanswered question log that feeds agent 05, the knowledge base gap analyzer. Inbox triage generates the voice capture data that feeds agent 13, the first draft writer. Starting with the right two agents seeds the data you need to ship the next three.
- 03
They are the canonical shapes
RAG over docs and inbox triage are the two cleanest patterns to teach a team. Once your team can ship those, every other agent on this list is a known shape with new data attached.

FAQ
Which of these 15 is fastest to ship?
A: Agent 01 (in-app AI help) and Agent 12 (conversational chatbot lead capture). Both are under 2 weeks for a senior engineer with a CLAUDE.md guide and real documentation to point at.
Do I need n8n to build these?
A: No, but it helps. n8n is the orchestration layer we reach for on agents 03, 06, 07, 10, and 14. Pure code works for agents 01, 02, 04, and 05.
Can a non-technical founder ship any of these?
A: With help, yes. Agents 01, 11, and 12 are available as no code configurations. The rest require real engineering. The AI Automation Playbook has the build plans.
What is the cheapest to run?
A: Agent 11 (error log triage) because it runs on a schedule and uses cheap models. Agents 02 and 15 are the most expensive due to real time voice and large context warehouse queries.
Which of these replaces a human role?
A: None outright. Agents 02 and 08 come closest. The rest shift human time from routine work to judgment calls. That is the right framing. Agents deflect work, they do not replace roles.
What stack do you use for most of these?
A: For orchestration, n8n. For reasoning, Claude (Sonnet for most, Opus for the two or three that need judgment). For retrieval, Pinecone or a small Postgres with pgvector. For voice, Retell AI plus Twilio. For the error log and data agents, direct SQL against the warehouse.
How do you prioritize which two to ship first?
A: Pick the two that touch your biggest bottleneck, then bias toward agents that feed each other. In-app AI help and inbox triage feed agents 05 and 13 with voice capture data, which is why we default to recommending those two first.