

TLDR
The 15 highest ROI agents for small teams in 2026 are support, sales, ops, and research agents with narrow scope and clear human handoff. Ship in-app AI help and inbox triage first. Both ship in under 3 weeks, both show ROI in month one, and both seed the data your next three agents need to learn from.
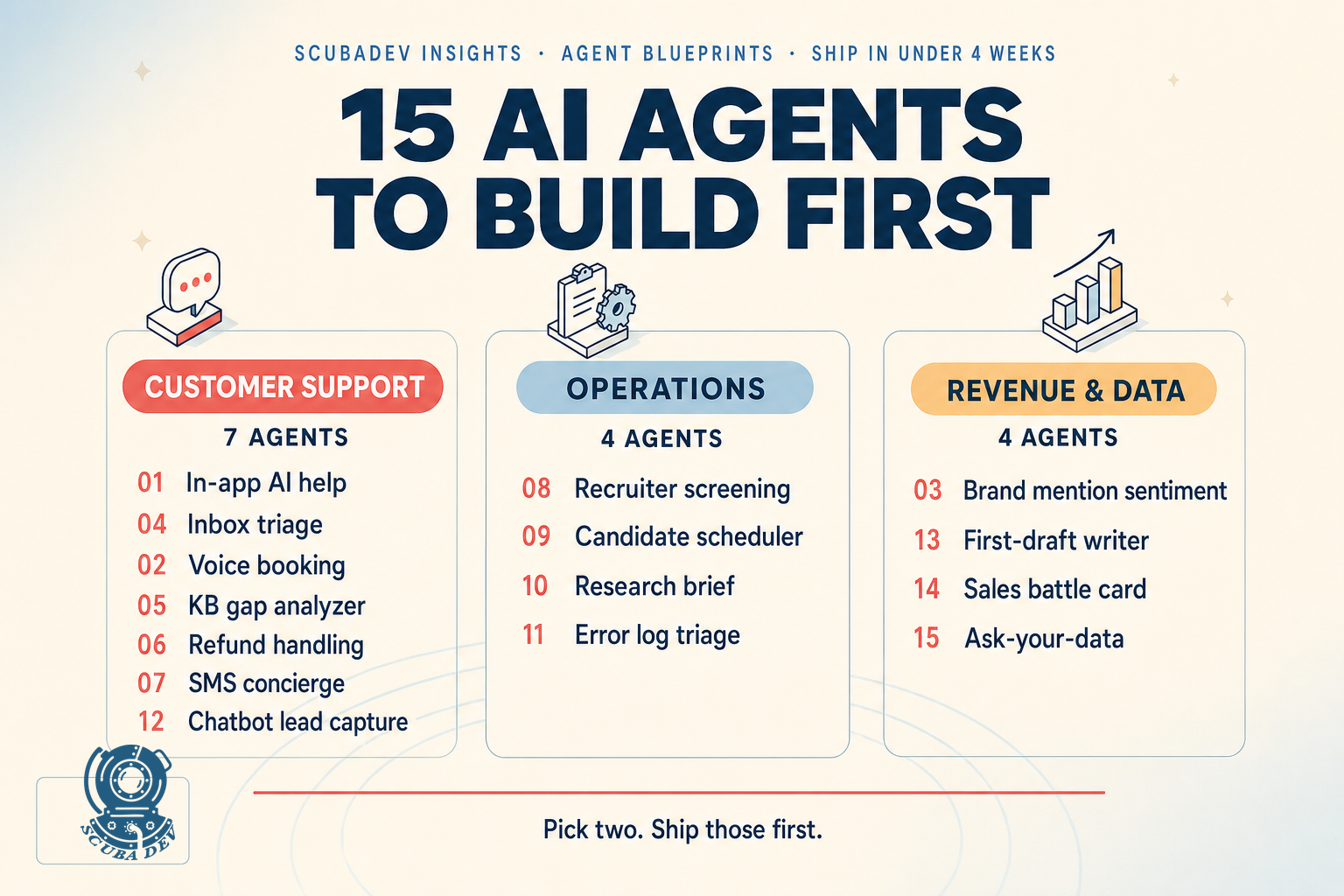
Ninety percent of AI agent content on the internet is demo code. This post is the opposite. These are 15 agents we have shipped, are shipping, or have designed blueprints for, each pulled from our live ideas library. Every one is production grade with the right stack, every one has a clear ROI model, and every one is within reach for a team of 2 to 10 with a few weeks of engineering time. Pick the two that touch your biggest bottleneck. Ship those first.
How to read this list
Every agent below is scored on three axes.
Effort. Weeks of engineering work for a typical small team. Momentum tier means 2 to 4 weeks. Deep end means 4 to 10 weeks.
Payback window. How fast the agent pays for itself in reduced headcount or faster revenue. Anything over 6 months we flag.
Stack bias. Our opinion on what to build with. Most of these run on n8n plus an LLM API plus a small database. For deeper stack discussion see our AI automation agency breakdown.
Each item links to the full blueprint in our ideas library. Click any agent below for the full breakdown, the build notes, and the canonical pattern.
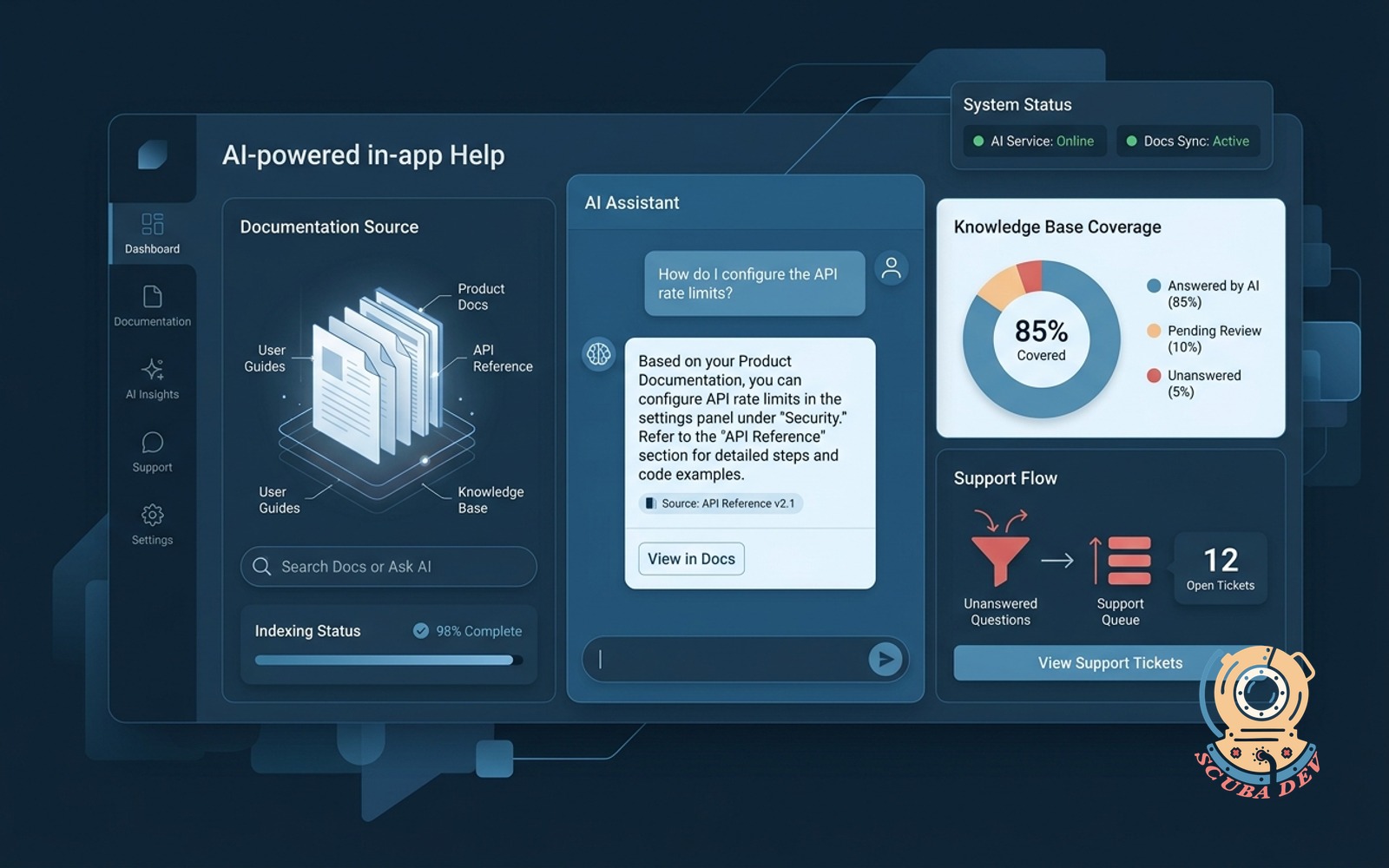
In-app AI help that reads your docs
Users ask questions in the app. The AI answers from your actual product docs. Unanswered questions flow to support.
No new auth surface, bounded token budget, the docs already exist in a format the model can ingest, and the ROI shows up in support tickets the next week. For any SaaS with more than 100 users and real documentation, this is agent number one in any serious ai agent development program. We run this pattern on seven client accounts and the average support ticket reduction in the first 90 days is 40 to 60 percent.
Build notes. Use a retrieval augmented approach over your docs, not fine tuning. Cheap model for question classification, capable model for the answer. Log every unanswered question. That log is the fuel for agent number five below.
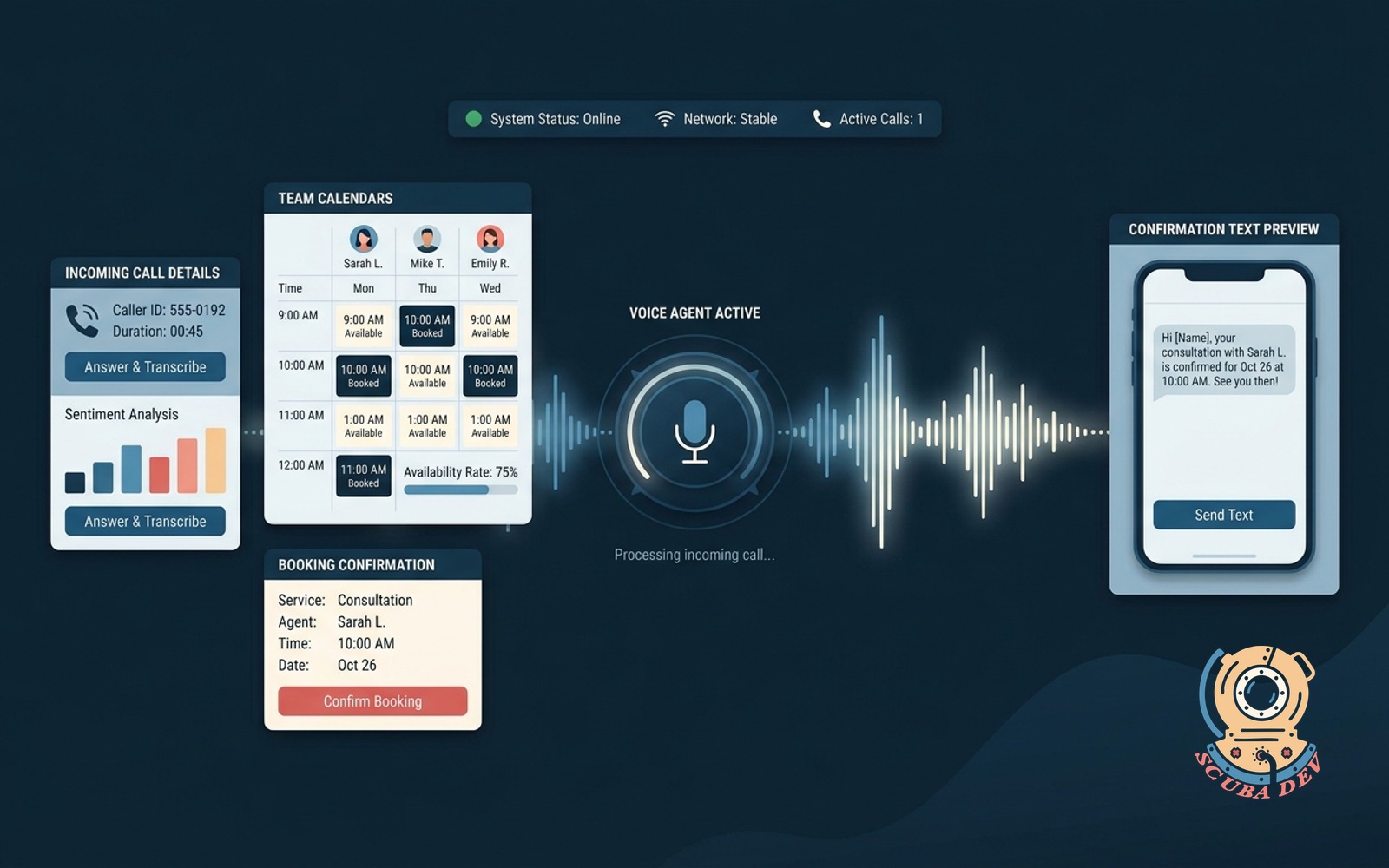
Voice-first booking agent
Answers the phone, reads the team calendars, books the right service with the right person, and sends a confirmation text.
This is the Mermaid Phone pattern. The stack is Retell AI or Vapi for voice, Twilio for telephony, Claude for reasoning, and whatever calendar the client already uses, Google Calendar, Cal.com, GoHighLevel, or Calendly. For any service business taking calls, salons, med spas, home service, small healthcare, this is the single highest ROI agent in the list because it replaces a part time receptionist role.
Build notes. Latency is the make or break metric. Under 1.5 seconds between caller speech and agent response is where callers stop noticing the agent is AI. Budget engineering time for latency tuning, not feature breadth. Features are cheap. Latency is the moat.
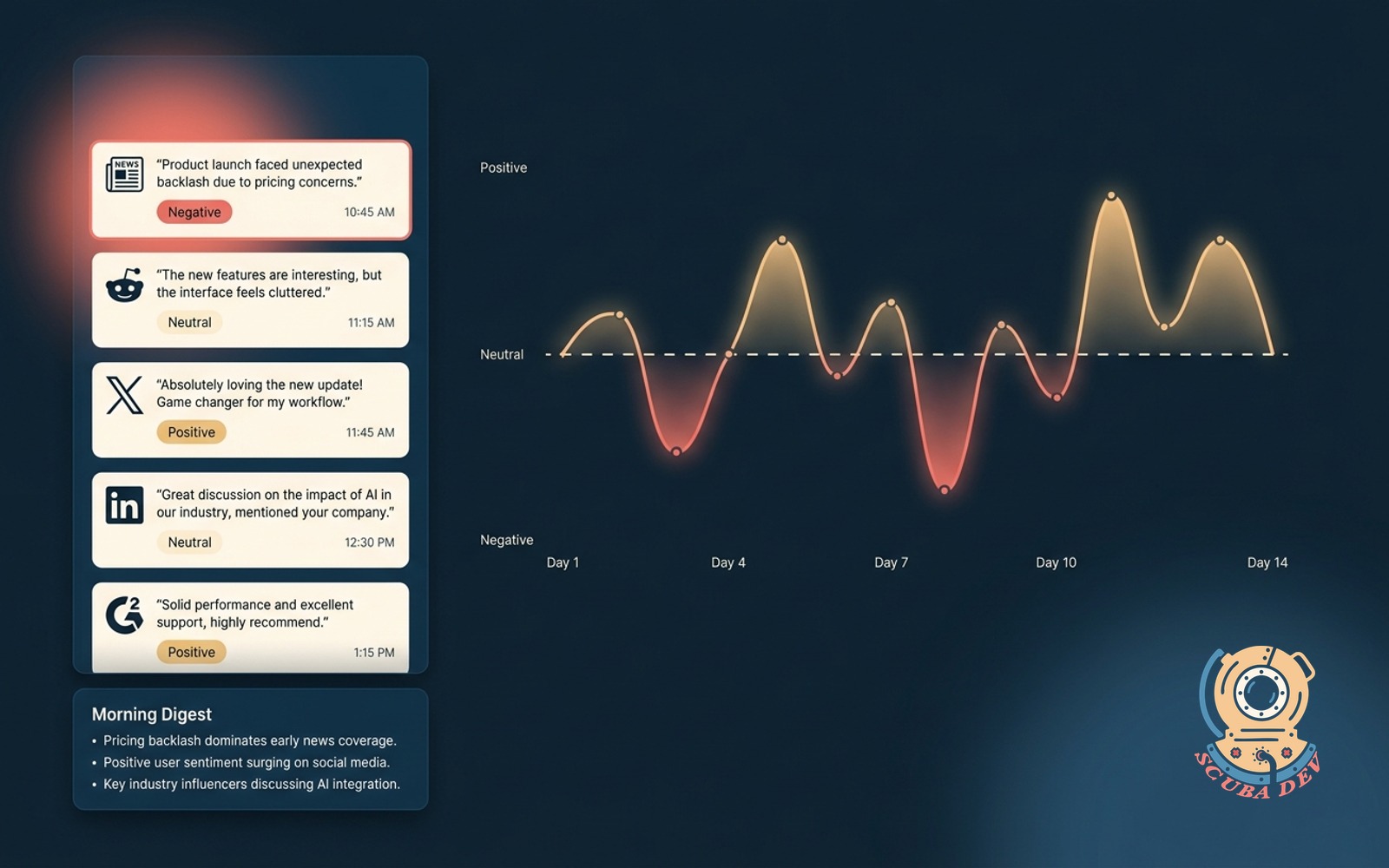
Brand mention agent with sentiment
Watches the web and social for your brand. Summarizes daily, flags negative mentions for response.
The trick is not the monitoring. Mention.com and Brand24 solved that part. The trick is the sentiment classifier that flags only what matters. Generic sentiment tools flag too many false positives. A brand specific classifier, trained on your past incidents, is the ROI.
Build notes. Start by labeling 100 past brand mentions as ignore, respond, or escalate. Use the labeled set as your classifier prompt. Log the classifier misses and relabel weekly for the first month. After that the model stabilizes and the human work drops off.

Inbox triage agent
Reads every new message, drafts the reply in your voice, files the rest, flags only what needs you.
This is the highest ROI agent for operators whose inbox is the bottleneck. Per the 2025 RescueTime report, knowledge workers spend 28 percent of their week on email. A triage agent that deflects 40 percent of that with a good filing system buys back roughly a day a week per person.
Build notes. Voice capture is the hard part. Feed the agent 200 of your past sent emails as the style guide. Run a two stage classifier, cheap model for category, capable model for draft. Never auto send. Always human approval. This is the single most popular ai agent development ask we get from operators, and it earns the attention.

Knowledge base gap analyzer
Clusters unanswered tickets into topics the knowledge base does not cover. Drafts the missing articles for approval.
This is the back half of agent number one. In-app AI help logs unanswered questions. This agent turns the log into articles. Together they compound, more articles, fewer unanswered questions, less support load, faster feedback loop. If you want a clean example of how to build an AI agent that gets smarter the longer it runs, this is the one. It is also a tidy agentic workflow pattern, two narrow agents feeding each other instead of one big one trying to do everything.
Build notes. Run it weekly, not in real time. Cluster the unanswered question log by topic embedding. Output is a ranked list of missing articles. A human reviews, the agent drafts, a human publishes. The publish step is what earns trust.
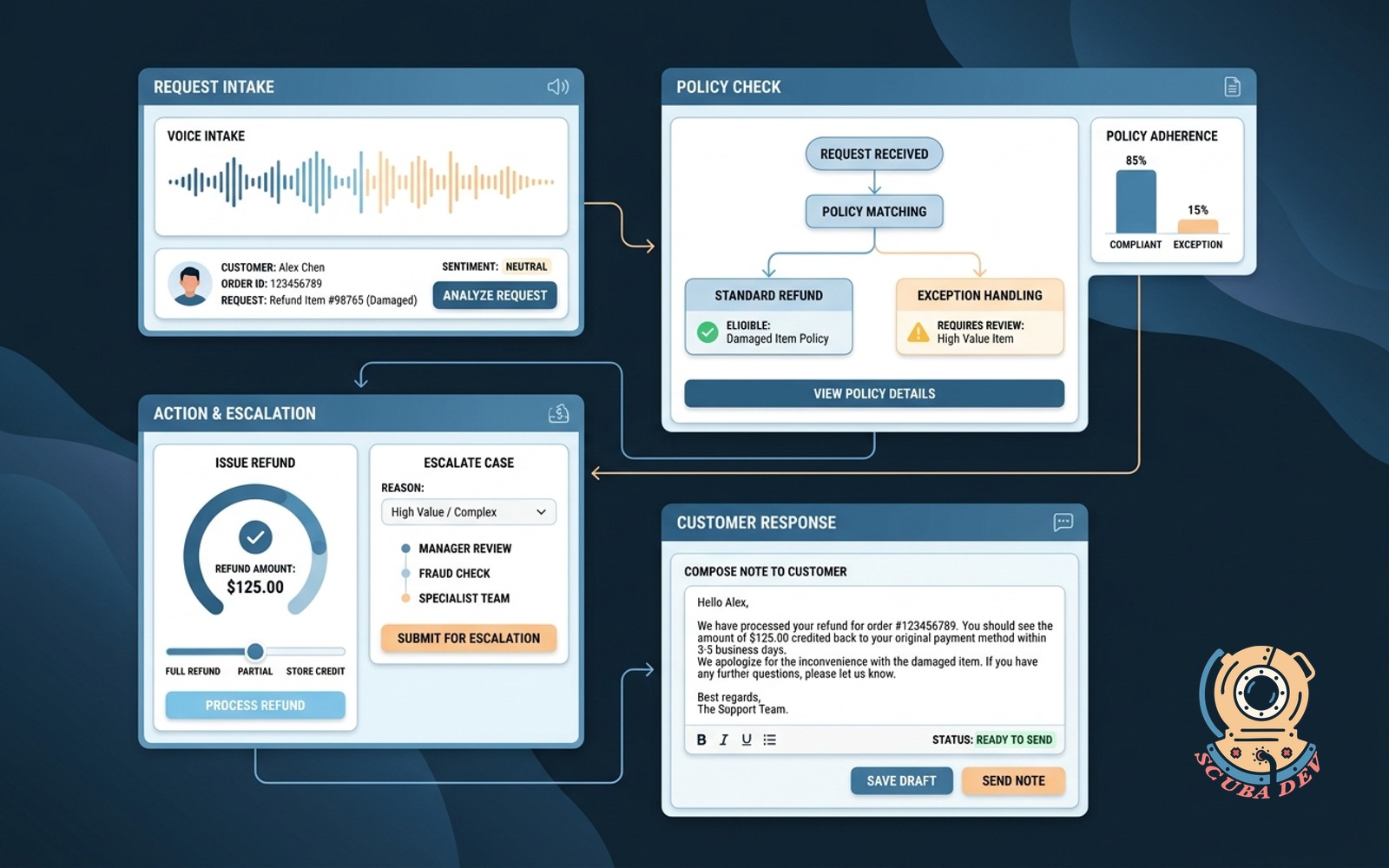
Refund handling agent
Hears the request, checks policy, issues the refund or escalates, writes the note back to the customer.
For ecommerce or subscription SaaS, refunds are the highest friction support interaction. Half of them are within policy and should be automatic. The other half require human judgment. The refund agent separates them.
Build notes. The policy has to be in structured form, not a PDF. The agent reads rules, not prose. Set the auto refund threshold conservatively at launch, say, any refund under $50 within 30 days of purchase. Expand the threshold as confidence grows. Log every decision with the exact rule it fired on.

Post-purchase SMS concierge
After the order ships, the buyer can text questions about sizing, care, or returns. AI answers in brand voice and escalates real issues.
This is an ecommerce specific agent that pays back fast because it catches refund and return intent before it becomes a dispute. The stack is Twilio SMS plus Claude plus whatever order system the client runs, Shopify or WooCommerce.
Build notes. Opt in is legally required, TCPA in the US. Send the opt in inside the order confirmation email. Keep the agent scoped to post purchase questions only, not cross sell. Crossing into promo kills trust and opt in rates fall off a cliff.
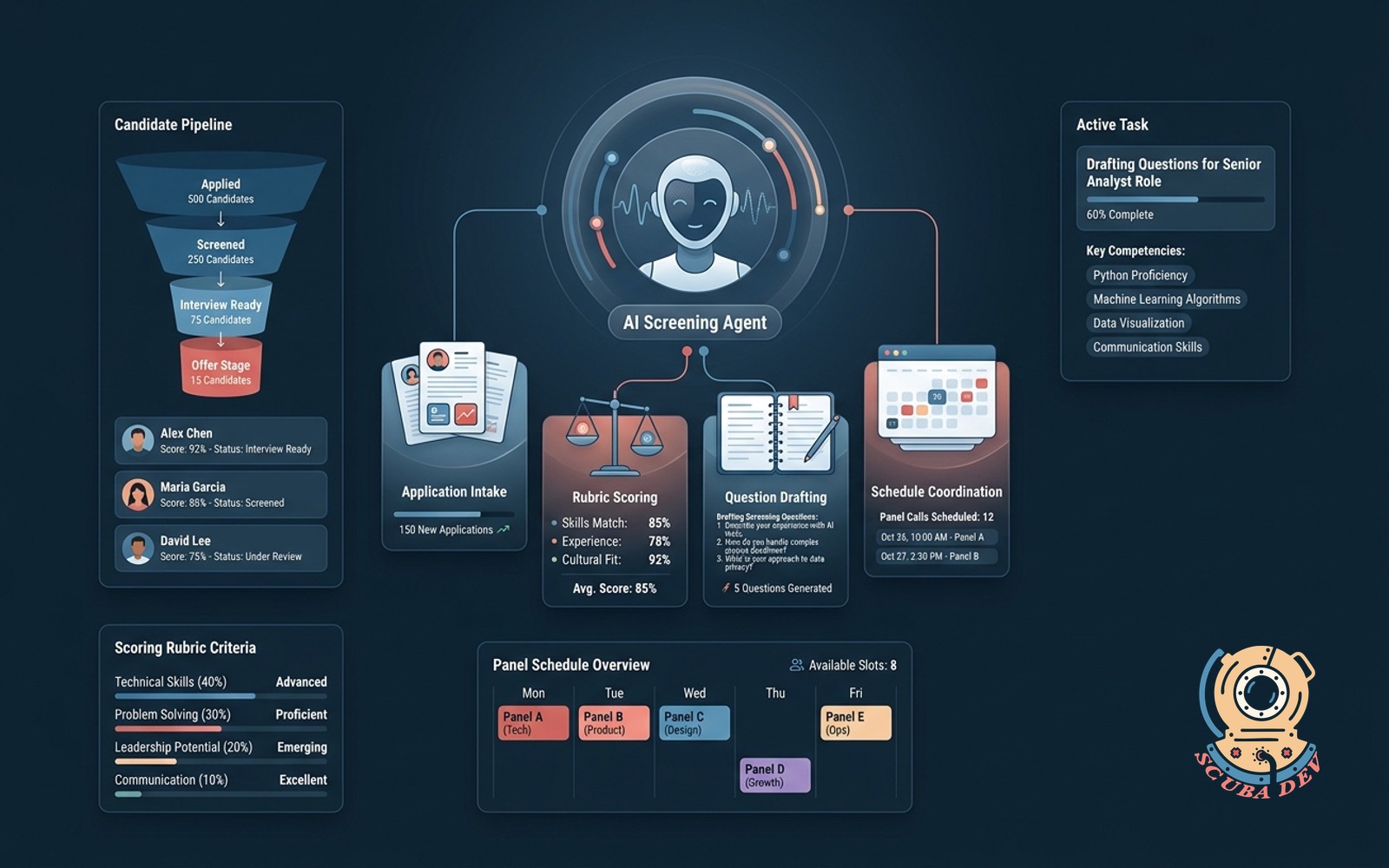
Recruiter screening agent
Reads applications, scores against the rubric, drafts screening questions and schedules panel calls.
Only build this if you hire at volume. For a team hiring 5+ roles per quarter, it saves a recruiter role. For a team hiring one role a year, it is over engineered. Know which side of that line you are on before you start the build.
Build notes. The rubric has to be written down. A vague rubric produces a vague screening agent. The ATS integration is usually the longest part of the build, whether you are on Greenhouse, Lever, or Ashby. Human review on every final schedule decision, without exception.
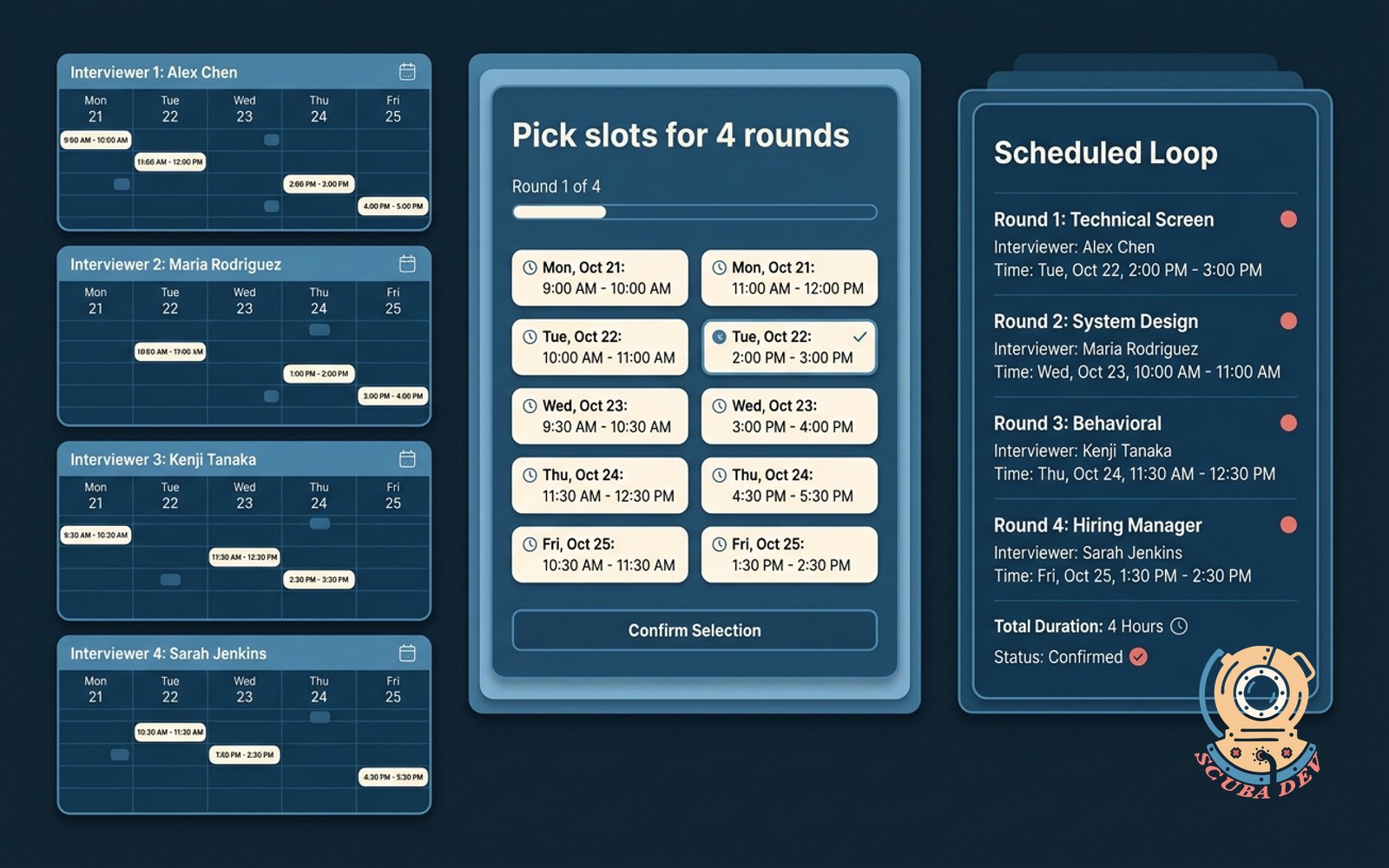
Candidate-screen scheduler agent
Syncs interviewer calendars, sends the candidate link, books the loop without the back-and-forth.
This is the cheaper cousin of agent eight. If you only need the scheduling piece, build this one. It also works for sales demos and partner calls, not just hiring. Any time you need a human loop scheduled across busy calendars, this is the shape.
Build notes. Calendly and Cal.com both solve 80 percent of this with no AI. Build the agent version only if your scheduling constraints are complex, multiple interviewers, timezone constraints, role specific slots. Otherwise just use Cal.com and move on to the next fight.

Research brief agent
You name the topic, the agent browses, collects sources, writes the brief and lists the open questions.
This is the agent that replaces 40 percent of a junior analyst week. For agencies and consultants, it is a direct margin improvement. For in-house teams, it is an output expansion. Same agent, different economics.
Build notes. Browsing is still the hard part of any custom ai agent that needs fresh data. Firecrawl and Perplexity API handle most cases. Output format has to be structured, sources, summary, open questions, or the brief becomes a dump. Structured output is the difference between something the team reads and something the team ignores.
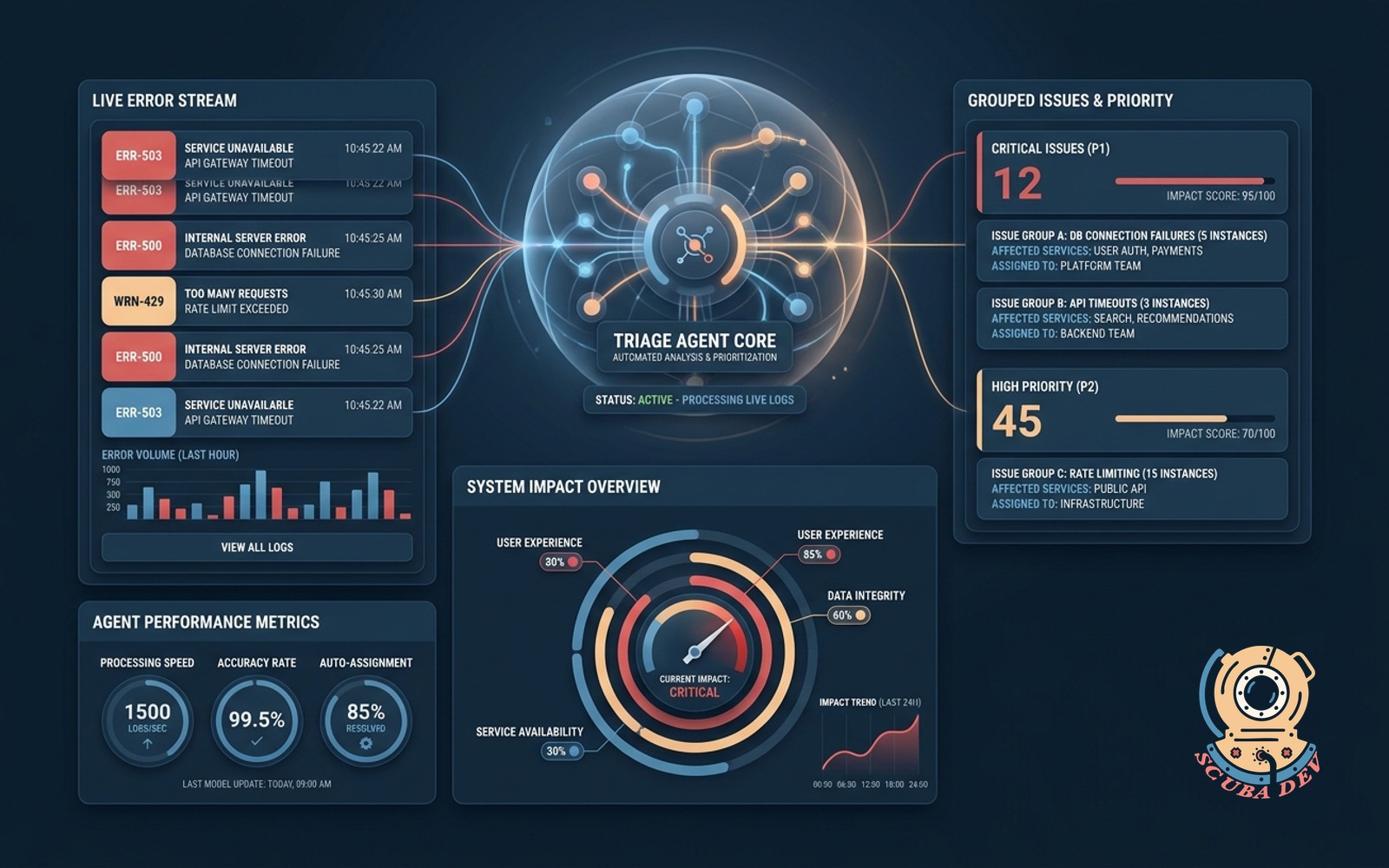
Error log triage agent
Reviews application error logs to group related issues and assign priority levels based on system impact.
This is the DevOps agent every team eventually needs. Sentry and Datadog have primitive versions built in. A dedicated agent with your own rules does better because it knows which errors map to which customer impact. That mapping is the value.
Build notes. Run it on a schedule, not real time. Output is a ranked incident list, not an alert. The human on call triages from the list. The agent should not wake people up. The moment it wakes the wrong person at 2 am, trust evaporates and the agent gets disabled.
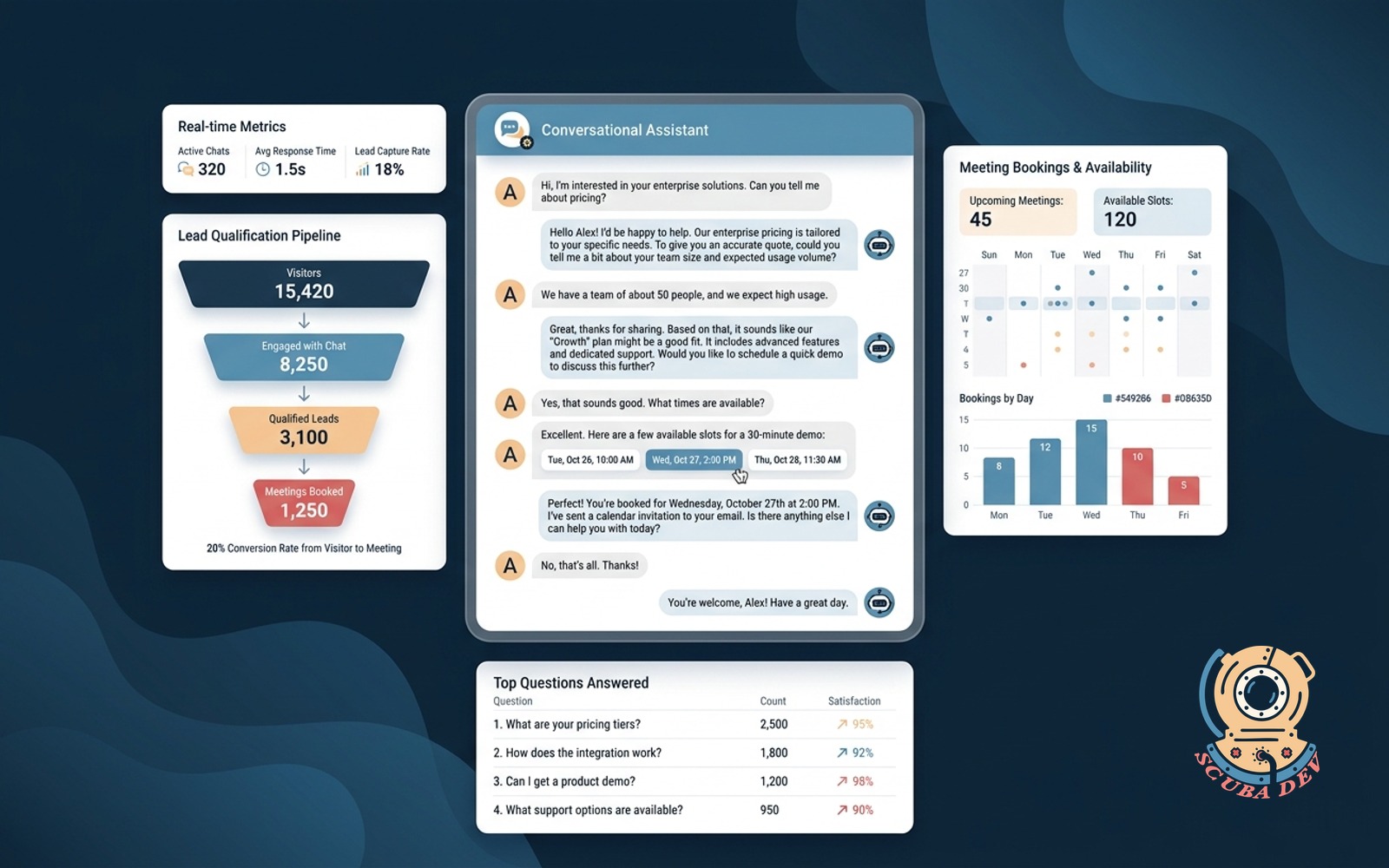
Conversational chatbot lead capture
Chat widget that replaces the contact form, qualifies visitors in natural language, books meetings, and answers top questions.
For any B2B site where the contact form is where leads go to die, this is a direct conversion improvement. We have seen 2 to 4x lift in qualified lead volume on client sites that replaced a form with a conversational agent. Same traffic, more qualified pipeline, no ad spend change.
Build notes. The qualifying questions need to be real. What is your budget asked badly turns leads off. Ask the agent to gather context and route, not interrogate. The difference is tone and ordering. Context first, ask second.
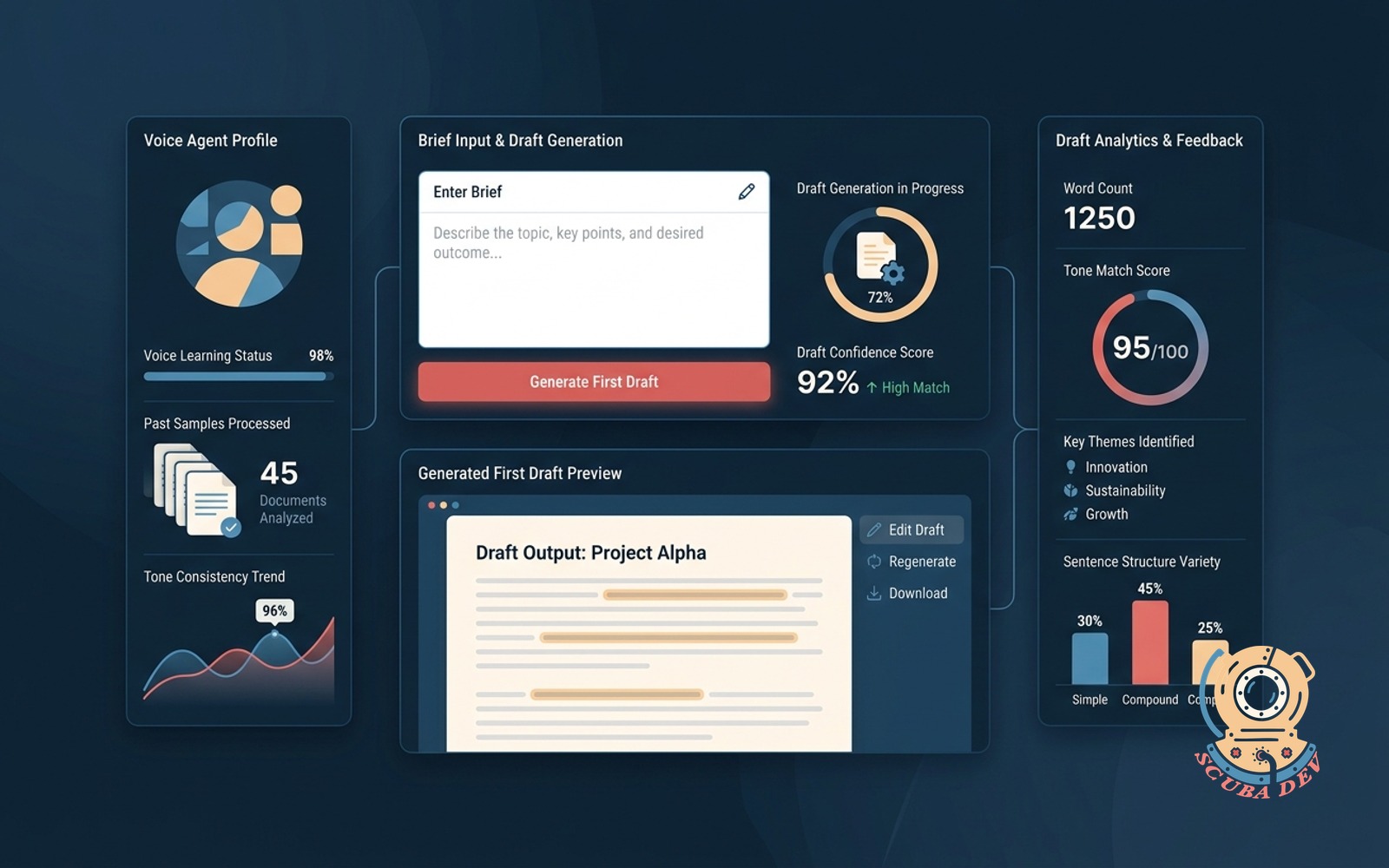
Brief-to-first-draft writer agent
Learns a single writer voice from past samples, takes a brief, and returns a first draft in that voice for the writer to edit.
For content heavy teams, this compresses the draft to publish cycle by 40 to 60 percent. The key word is single. A generic write like our brand agent produces bland output. A per writer agent that has ingested that writer last 20 pieces produces something the writer actually wants to edit.
Build notes. Voice capture is 80 percent of the build. Get 10,000+ words of past writing per writer. Fine tuning is overkill for this. Long context in prompt is enough and far cheaper to maintain across model versions.
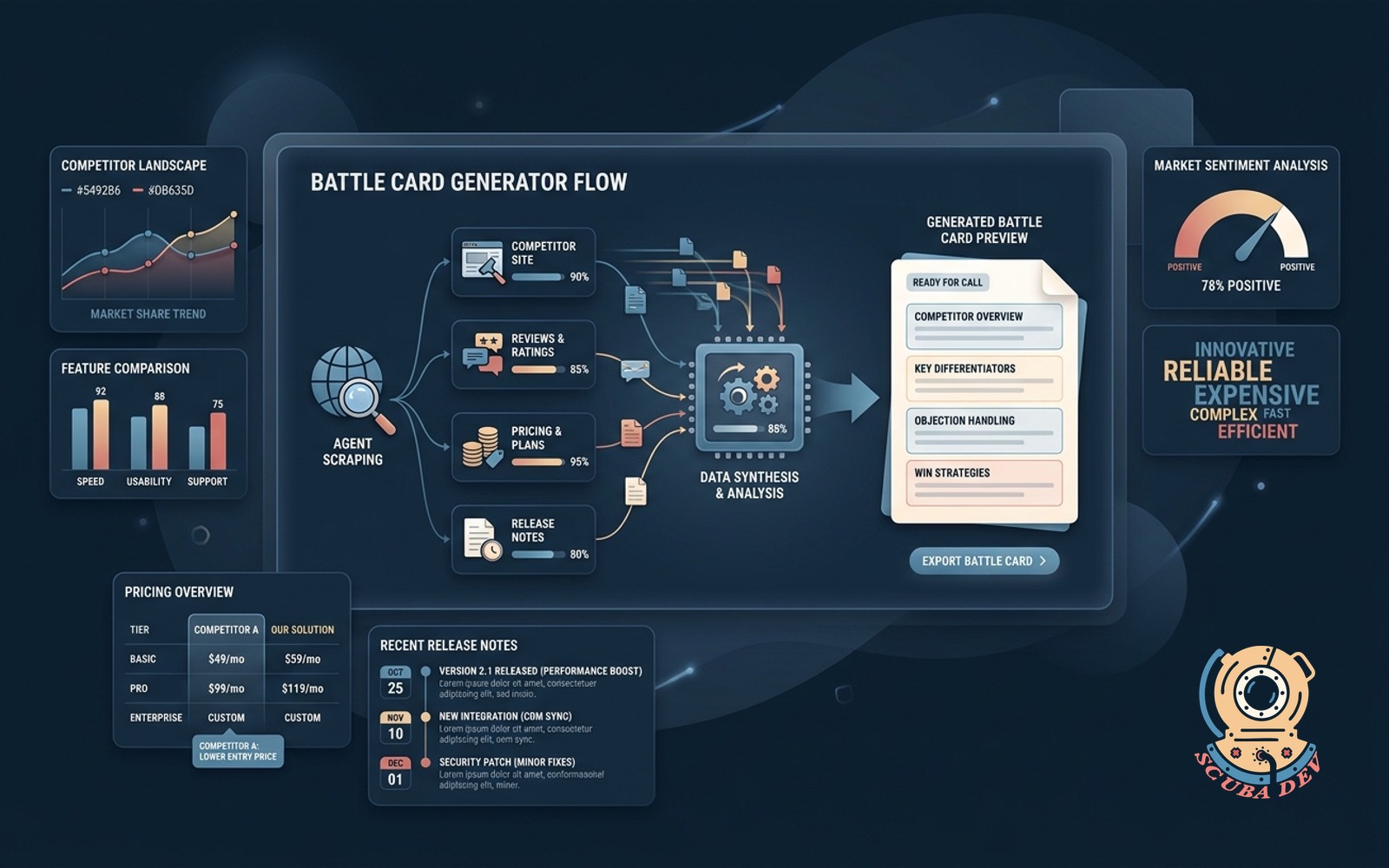
Sales battle card generator
Scrapes competitor site, reviews, pricing, and release notes to produce a one-page battle card before every rep call.
For sales teams over 5 reps selling into competitive markets, this is a real productivity lever. The card has to be dated and automatically regenerated weekly, because stale battle cards are worse than no battle cards. A rep citing something the competitor stopped doing six months ago burns credibility in one call.
Build notes. Competitor pages change. Monitor for deltas and surface them as what changed this week in the battle card. Ingesting G2 and Capterra reviews is where the real insights come from, not the marketing site.
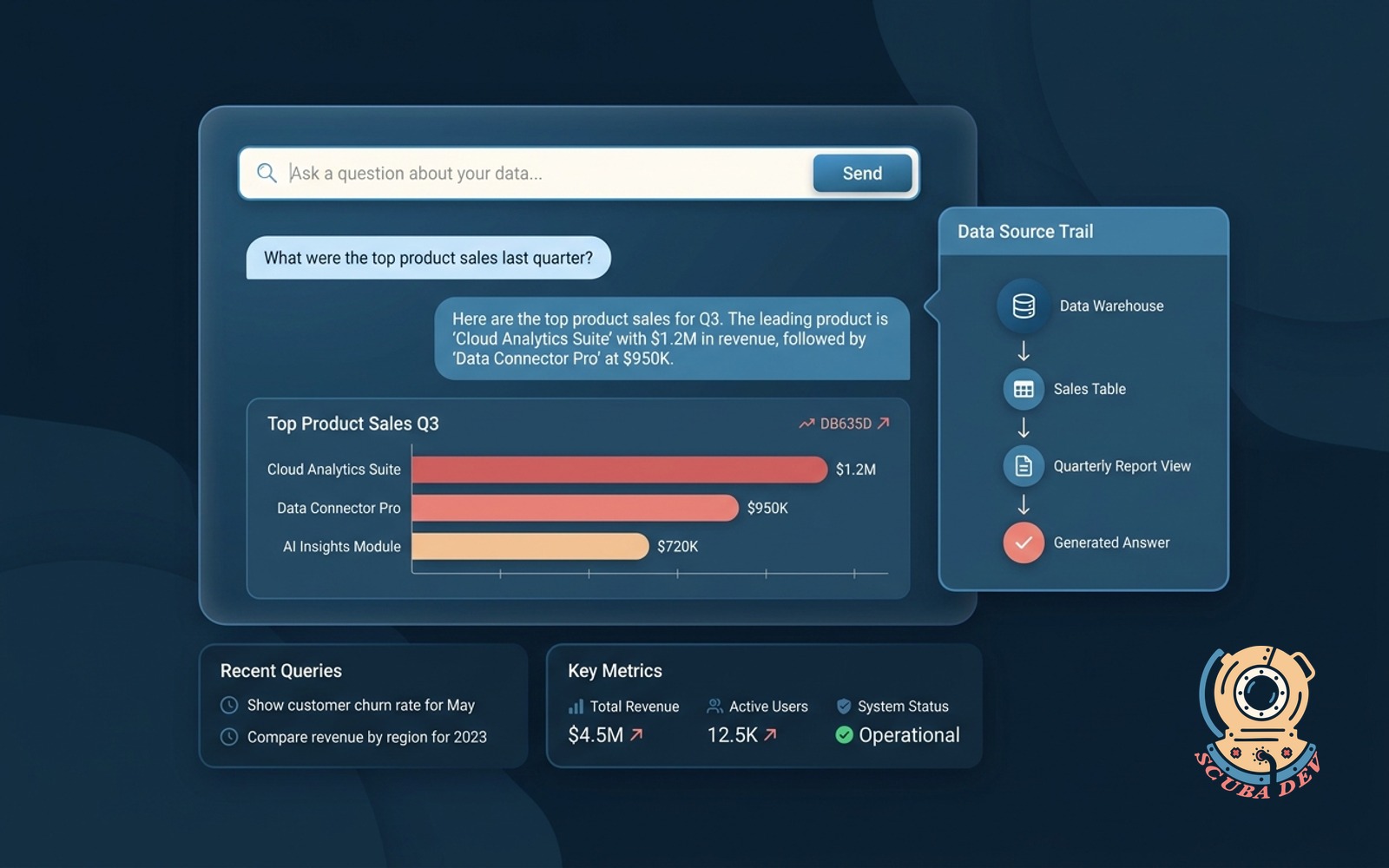
Ask your data conversational agent
Plain English questions against your warehouse return an answer, a chart and a source trail.
This is the deep end agent on the list. It is 4 to 10 weeks of work and requires a real data model underneath. For companies with a warehouse, Snowflake, BigQuery, Postgres, and a data team under capacity, it unlocks self serve analytics that replace a lot of BI ticket volume. Think of it as the canonical multi-agent system entry point, once the warehouse agent works, every other team agent learns to ask it for numbers.
Build notes. Trust comes from the source trail. Every answer must link to the SQL it ran and the tables it touched. Without the trail, operators do not trust the output, and the agent gets abandoned in month two.
Which two to ship first
If you have to pick two, pick agent 01, in-app AI help, and agent 04, inbox triage. Here is why.
They address the two universal bottlenecks of a small team, support load and communication load. Every company has both. Neither requires a data infrastructure investment. Both ship in under three weeks. Both show measurable ROI inside the first 30 days.
The second reason is compounding. In-app AI help generates the unanswered question log that feeds agent 05, the knowledge base gap analyzer. Inbox triage generates the voice capture data that feeds agent 13, the first draft writer. Starting with the right two agents seeds the data you need to ship the next three. That is how a real agentic workflow grows inside a company without a chief AI officer to justify it.
What they all have in common
Pattern across all 15 agents.
- Narrow scope. Every agent on this list does one thing. Personal AI assistant is not on the list because it is not an agent, it is a marketing category.
- Human handoff. Every agent has a clear escalation path. A refund over $50. A brand mention with sentiment above a threshold. An email with an unknown category. Handoff is not a failure mode, it is the most important feature.
- Bounded data surface. Agents that read docs, calendars, inboxes, and logs beat agents that read the internet. Bounded data makes the agent cheaper, faster, and safer.
- Observability built in. Every agent logs inputs, outputs, and human overrides. Without observability, you cannot debug, cannot tune prompts, and cannot make the case for expansion. This is the error log triage pattern applied to the agent itself.
FAQ
Agent 01, in-app AI help, and agent 12, conversational chatbot lead capture. Both are under 2 weeks for a senior engineer with a CLAUDE.md guide and real documentation to point at.
No, but it helps. n8n is the orchestration layer we reach for on agents 03, 06, 07, 10, and 14. Pure code works for agents 01, 02, 04, and 05. See our n8n vs Zapier breakdown for the decision framework.
With help, yes. Agents 01, 11, and 12 are available as no code configurations. The rest require real engineering. The AI Automation Playbook has the build plans.
Agent 11, error log triage, because it runs on a schedule and uses cheap models. Agents 02 and 15 are the most expensive due to real time voice and large context warehouse queries.
None outright. Agents 02 and 08 come closest. The rest shift human time from routine work to judgment calls. That is the right framing. Agents deflect work, they do not replace roles.
For orchestration, n8n. For reasoning, Claude, Sonnet for most, Opus for the two or three that need judgment. For retrieval, Pinecone or a small Postgres with pgvector. For voice, Retell AI plus Twilio. For the error log and data agents, direct SQL against the warehouse. Minimal, boring, and stable across model versions.
Pick the two that touch your biggest bottleneck, then bias toward agents that feed each other. In-app AI help and inbox triage feed agents 05 and 13 with voice capture data, which is why we default to recommending those two first.
Next steps
Three ways to move from reading to shipping.
- Automate pillar hub, every agent build pattern we run and the retainer structure behind the work.
- AI implementation solution, scoping, build, and deploy for teams that want the first two agents shipped this quarter.
- The AI Automation Playbook, a field guide to ai automation across ops, marketing, and product, with the tooling landscape, agent archetypes, failure modes, and TCO framework behind every build above.
Related topics, automation ideas, scale patterns, ship patterns.
Idea detail