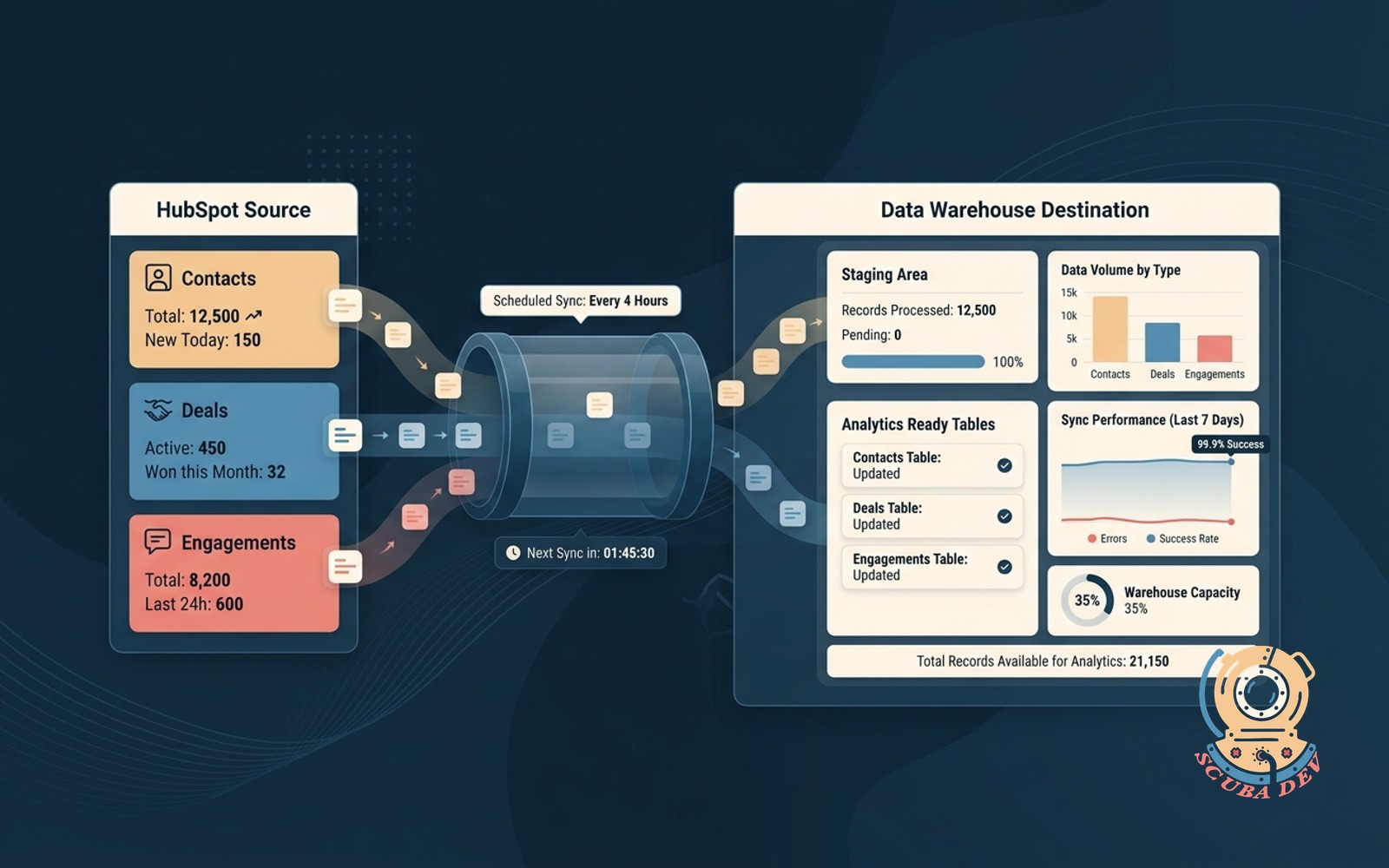
HubSpot to warehouse pipe
HubSpot contacts, deals and engagements land in the warehouse on a schedule, ready for analytics.
Possibilities
Where this could go
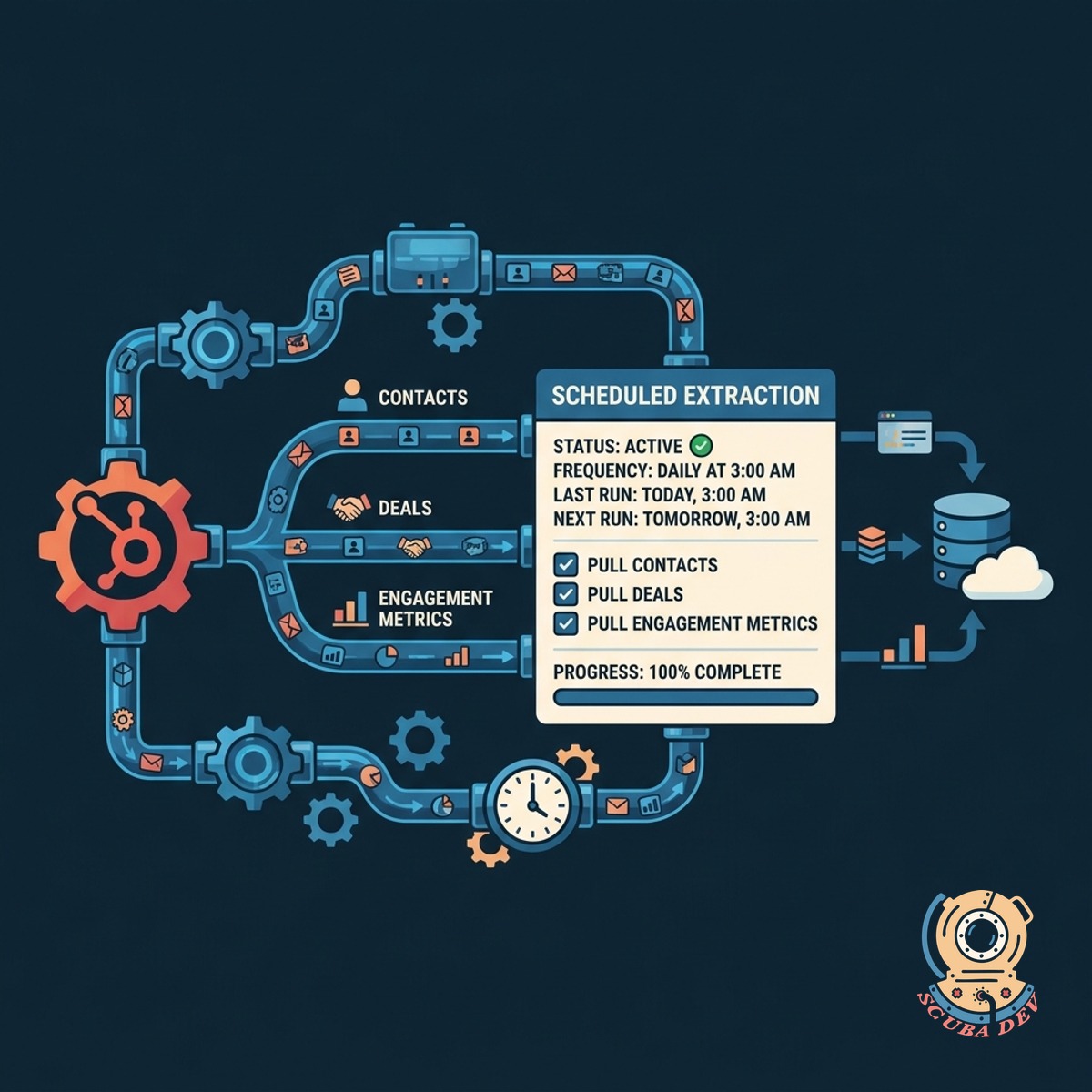
Scheduled HubSpot Data Extraction Pipeline
Pull your contacts, deals, and engagement metrics from HubSpot automatically based on a reliable schedule.
- Connect HubSpot API
- Extract contacts and deals
- Pull engagement metrics
- Run on custom schedules

Direct Load To Cloud Warehouses
Send your raw HubSpot data directly into your preferred cloud data warehouse for secure and centralized storage.
- Connect to Snowflake
- Load into Google BigQuery
- Sync with Amazon Redshift
- Maintain data integrity
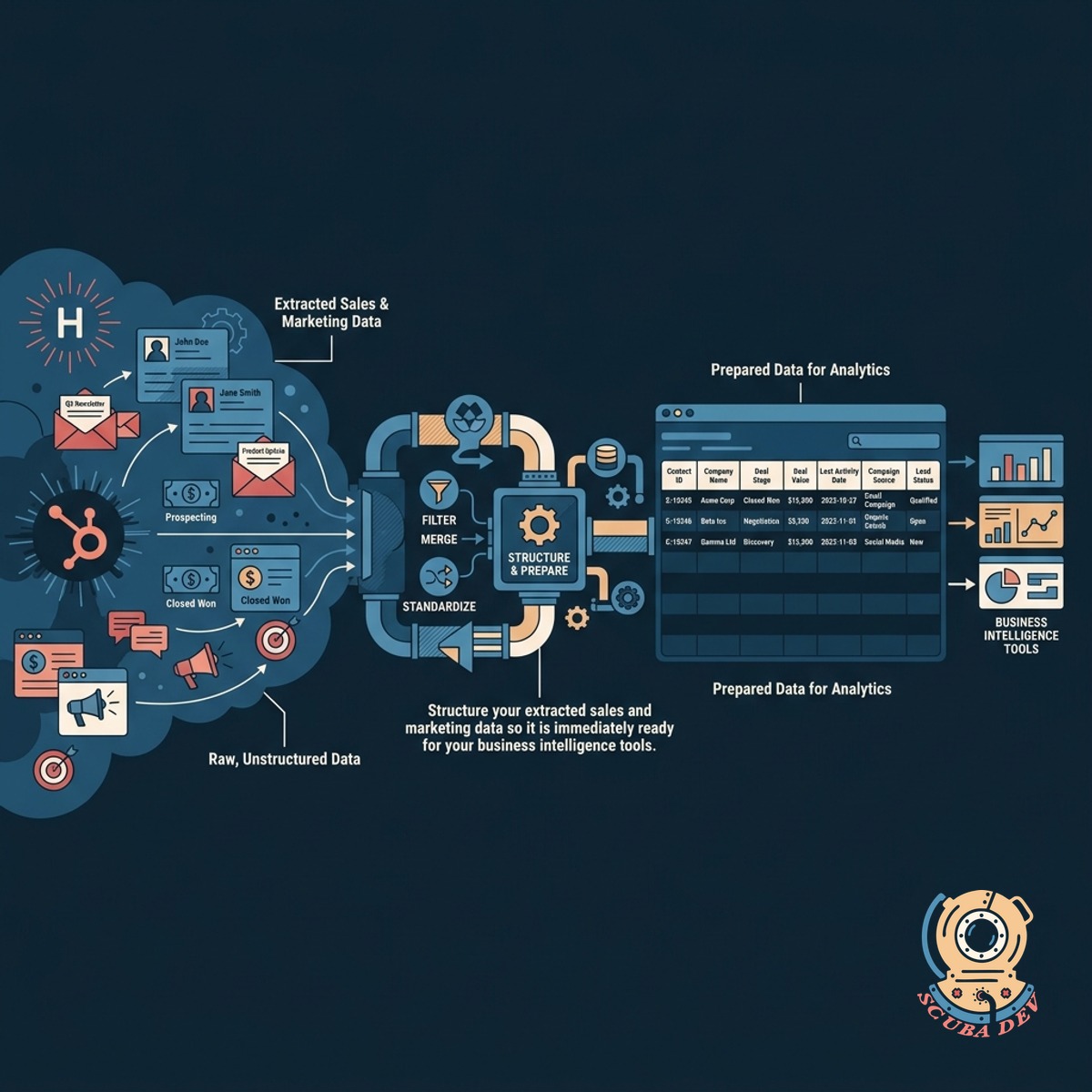
Prepare HubSpot Data For Analytics
Structure your extracted sales and marketing data so it is immediately ready for your business intelligence tools.
- Clean raw JSON data
- Map custom HubSpot properties
- Build relational tables
- Connect to BI tools
Questions
Things people ask
Which data warehouses do you support for this pipeline?
We build pipelines that load HubSpot data into major cloud data warehouses including Snowflake, Google BigQuery, Amazon Redshift, and PostgreSQL.
How often does the data sync from HubSpot?
The pipeline runs on a schedule that fits your requirements. We can configure it to sync daily, hourly, or at custom intervals depending on your analytics needs.
Does this include custom properties from HubSpot?
Yes. The pipeline extracts all standard objects along with any custom properties you have configured for your contacts, companies, and deals.
What happens if the HubSpot API rate limit is reached?
The pipeline includes built in logic to handle API rate limits. It will pause and retry requests automatically to ensure all data is extracted without errors.
Can we extract email and meeting engagement data?
We can pull all engagement data logged in HubSpot. This includes emails, calls, meetings, tasks, and notes associated with your contact and deal records.
Do you use third party tools like Fivetran or Airbyte?
We can implement the pipeline using managed services like Fivetran or Airbyte, or we can build a custom Python extraction script depending on your infrastructure preferences.
How is the data structured once it reaches the warehouse?
The data lands in raw tables first. From there, we can use tools like dbt to transform the raw data into clean, relational models that your analytics team can query easily.