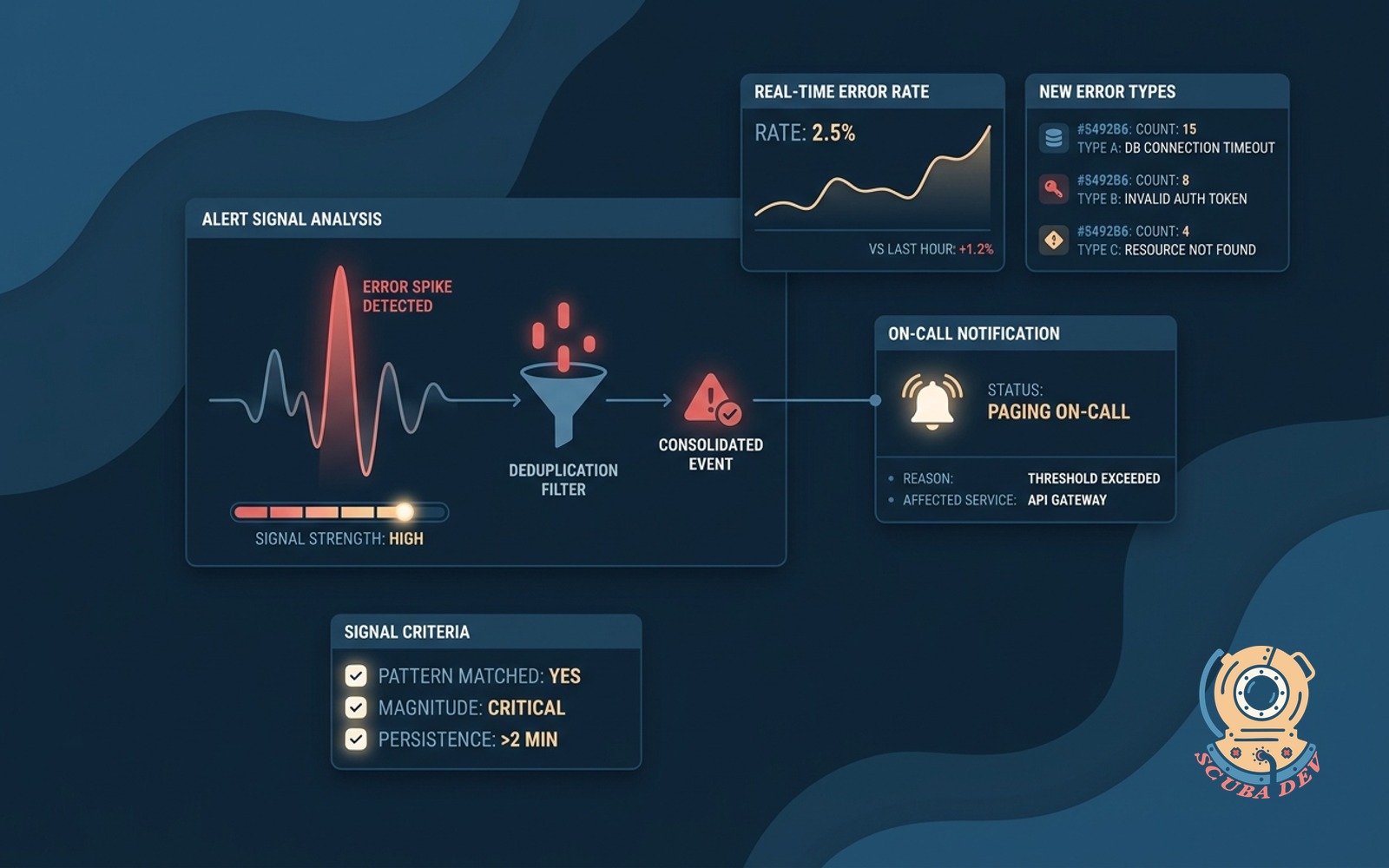
Error spike alerts
Watches the error rate and new error types, only pages the on-call when the signal is real and deduplicates.
Possibilities
Where this could go

Filter Out The Noise
The system groups identical errors and only triggers alerts for genuine anomalies to prevent alert fatigue.
- Group recurring stack traces into a single incident ticket.
- Suppress alerts for known low-priority background job failures.
- Set custom thresholds for when an error volume becomes actionable.
- Route alerts to specific teams based on the service owner.
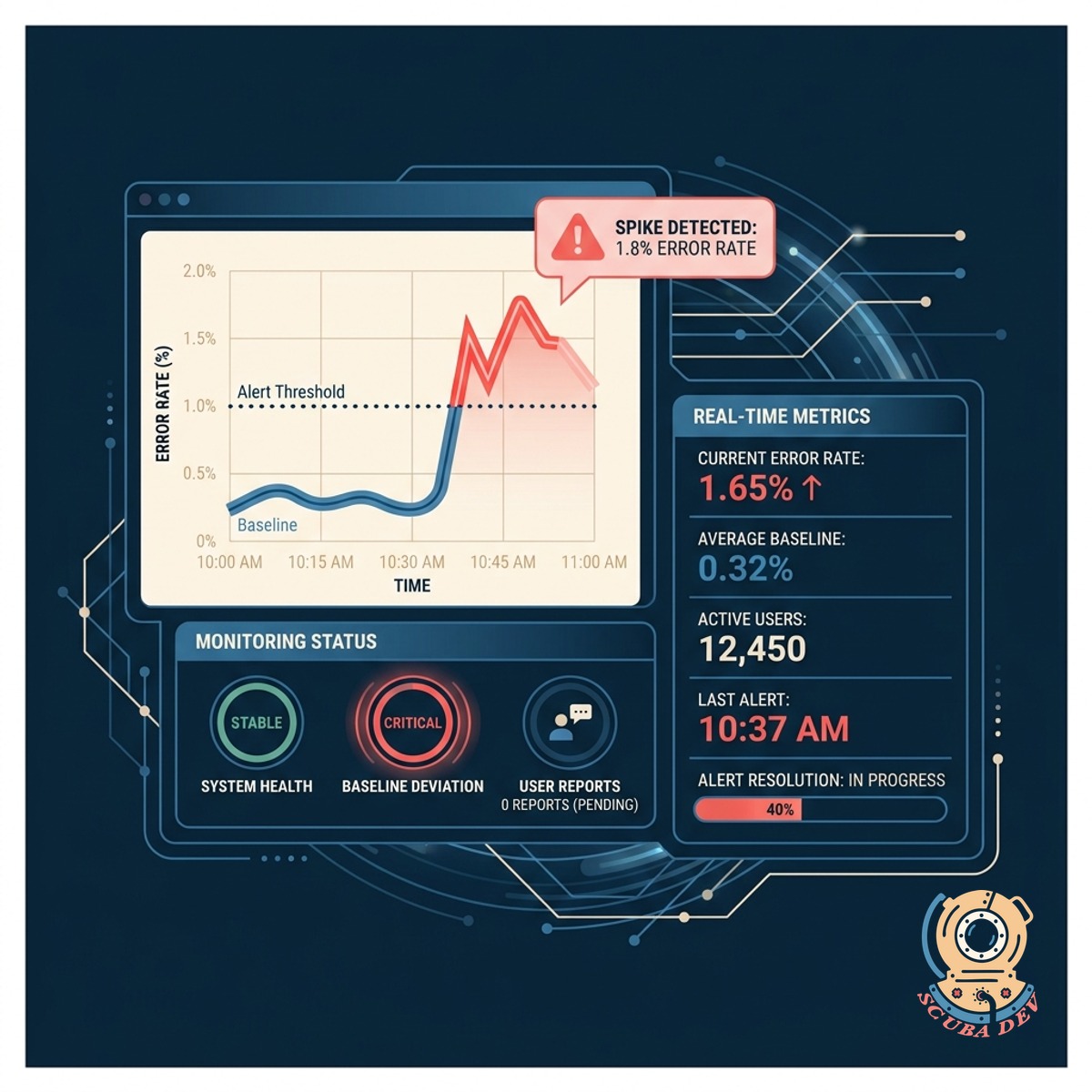
Track Error Rate Baselines
Monitor your application error rates continuously to detect sudden spikes before users report them.
- Establishes normal error rate baselines
- Triggers alerts on percentage deviations
- Connects with Sentry and Datadog
- Tracks errors across multiple environments

Catch Unseen Error Types
We automatically flag new exceptions that have never appeared in your logs before so you can investigate immediately.
- Compare incoming stack traces against your historical error database.
- Highlight the exact line of code where the new exception originated.
- Attach relevant deployment tags to see which release caused the issue.
- Send a dedicated notification when a previously unseen error type occurs.
Questions
Things people ask
Which error tracking tools do you support?
We integrate with standard industry tools like Sentry, Datadog, and Bugsnag. We can also build custom webhooks for proprietary logging systems.
How does the system deduplicate errors?
We integrate directly with your existing incident management tools like PagerDuty, Slack, and Jira. You can configure routing rules to ensure the right team gets paged in their preferred channel.
Can we set different thresholds for different environments?
The system calculates a rolling baseline of your normal error rates over the past week. When the current error volume exceeds this baseline by a configurable margin, we trigger an alert. You can adjust the sensitivity to fit your traffic patterns.
How do you determine what a real signal is?
Yes, you can mute specific error classes or set them to log without paging anyone. This keeps your on-call rotation focused on critical issues while still recording minor faults for later review.
Does this integrate with our incident management platform?
We support all major backend and frontend languages through our standard SDKs. You drop the library into your application, and we automatically parse the stack traces regardless of the framework you use.
What happens if a known error suddenly spikes?
The system tracks the frequency of all errors, even known ones. If a low-priority background error suddenly spikes above its typical volume, it will trigger a new alert for investigation.
How long does it take to establish an error baseline?
The system typically needs a few days of normal traffic to establish a reliable baseline. You can manually adjust the sensitivity during this learning period to avoid missed alerts.